Retrieval System based on Region Algebra
1. Introduction
Recent development of techniques for tag-annotation enables us to annotate huge amounts of text with various types of additional information, and to search or extract information using the annotations. By searching text with a complex request instead of using keyword search, we can omit complex analysis of text after the search, because the text annotations already provide the information which we would achieve from such analysis.
XML is the most general framework for annotating text with several types of information. Query languages, such as XPath and XQuery, have been constructed for XML, and many XML databases implement these query languages. However, these XML databases cannot be applied to a huge textbase and cannot treat the crossing of tag regions because of the definition of XML. For many types of information that might be used for annotation, there is no guarantee that tag regions never cross each other.
In this section, we describe a retrieval system for tag-annotated text based on the region algebra. We extend the region algebra, which is defined as a set of operations for region sets, to enable the system to retrieve text fragments quickly from a huge tag-annotated textbase. We incorporate the variables in the framework of region algebra to enable the system to connect text fragments which lie in distant positions but are nonetheless related. We also describe a fast algorithm to retrieve text fragments matching a query formulated in region algebra and containing variables.
2. Region Algebra
Region algebra is defined as "a set of operations between sets of regions". Table 1 shows an example of operations of region algebra.
| A |
Regions of A containing a region of B |
A |
Regions of A contained in a region of B |
A |
Regions containing both region of A and region of B |
A |
Regions of A or regions of B |
A |
Regions beginning with a region of A and ending with a region of B |
For the operations in Table 1, a fast algorithm is proposed in [Clarke et al. 1995] on the presupposition that there is no nested structure in an argument set of regions. That is, a region in an argument set of regions for a operation never contains the regions in the same set of regions. An algorithm that considers nested structures is proposed in [Jaakkola et al. 1999]. However, the latter algorithm cannot be applied to a huge textbase because the algorithm needs to check all regions of argument sets to evaluate the operation. So, we extend the former algorithm to enable it to calculate regions accurately when nested structures exist in argument sets of regions.
3. Index structure
We construct indexes for words, tags, and attribute-value pairs which appear in each tag. The indexes consist of the list of positions in which these three types of token appear, and depth information. The depth information is used to match a beginning tag and a corresponding ending tag easily, and to recognize the parent-child relations of tag regions easily while the algorithm evaluates the operations. Using this simple index structure, our system can be applied to a huge textbase.
4. Search algorithm for nested regions
Figure 1 shows an algorithm for some of the operations. The left figure shows the algorithm proposed in [Clarke et al. 1995], and the right figure shows our algorithm. These algorithms search for the first region matching to the query 'A ![]() B'. The function τ(Q,k) return the first region matching 'A' beginning at or after k. The function ρ(Q,k) return the first region matching 'A' ending at or after k. In our algorithm, after the algorithm finds the region matching 'A
B'. The function τ(Q,k) return the first region matching 'A' beginning at or after k. The function ρ(Q,k) return the first region matching 'A' ending at or after k. In our algorithm, after the algorithm finds the region matching 'A ![]() B', it searches regions matching 'A' containing the former region of 'A
B', it searches regions matching 'A' containing the former region of 'A ![]() B' and outputs the widest region of 'A
B' and outputs the widest region of 'A ![]() B'. We also improved an algorithm for the other operations in the same way to search regions considering the nested structure of regions.
B'. We also improved an algorithm for the other operations in the same way to search regions considering the nested structure of regions.
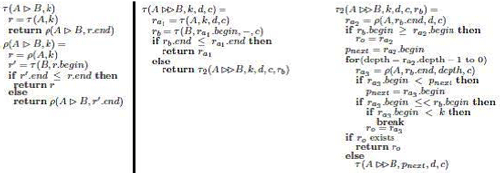 Figure 1. Search Algorithm
Figure 1. Search Algorithm5. Incorporating variables
By incorporating variables into region algebra, the relation between the fragments of text in distant positions can be specified by the variables and the information in tag-annotated text. In the example of tag-annotated text in Figure 2, the relation between the verb "activate" and its subject "p53" is expressed by matching of the values of attribute "arg1" in the beginning tag of "word" region containing "activate" and attribute "id" in the beginning tag of "phrase" region containing "p53". This relation is expressed by the following query in region algebra extended with variables.
[sentence] ![]() (([word arg1="$s"]
(([word arg1="$s"] ![]() activate)
activate) ![]() ([phrase id="$s"]
([phrase id="$s"] ![]() P53))
P53))
<sentence sentence_id="27426f"> |
etermining which values can be substituted for the variables requires very complex computation, since the algorithm determines the value of all variables at the same time, including all appearances of the same variable. The algorithm determines the value of variables one by one by using the partial restriction in the query. After the values for all variables are determined, it also executes the query, with the values substituted for their corresponding variables. This action checks that the substitution is correct. Moreover, the value of each variable depends on the values of the variables which have already been determined, in consideration of dependency relations among variables.
The search algorithm for the query containing variables proceeds as follows. (Here we assume that the algorithm searches sentences satisfying the condition of a query to simply the algorithm.)
- Search sentences containing all words appearing in the query.
- Determine the value of variables in the sentence found in Step 1.
- Substitute the value into variables in the query, and execute the query in the sentence.
The value of variables is determined with the following algorithm.
- Make sub-queries from the query.
- Pick up a sub-query which contains one variable and to which estimated number of regions match is least from the sub-queries.
- Execute the sub-query in the sentence with ignoring the part of variables.
- Determine the value for the variable by the result text retrieved in Step 3.
- Substitute the value into the variable in the give query.
- Repeat the algorithm from Step 1 until it determines the value of all variables.
Before the calculation of value for variables, the algorithm narrows the target sentences by the keyword search. That is, it calculates value of the variables only in the sentence containing all words appearing in the query. By this narrowing, the algorithm can search sentences matching the query efficiently. Moreover, in the calculation of the value for variables, the algorithm can determine the value efficiently by determining the value for variables in ascending order of the number of candidate values which can be substituted for the variable.
6. Experiments
We implemented the above algorithm in our system, MEDIE. The target data are a set of abstracts from MEDLINE which have been parsed by the Enju parser and which have been tagged with a named entity recognizer. Table 2 shows the size of data used. We presented some queries to our system and timed the search process. Table 3 shows search requests used in the experiment. We converted the search requests into queries in region algebra as shown in Figure 4 and sent the queries to our system. Table 5 shows search time and the number of results per query. The result shows that our system can quickly find search results in this huge amount of data.
| # articles | 14,785,094 |
# abstracts |
7,291,857 |
# sentences |
70,935,630 |
# words |
1,462,626,934 |
The size of raw text of MEDLINE |
9.3 GB |
The size of tag-annotated Text |
292 GB |
The size of inverted position index |
219 GB |
1 |
P53 activates WAF1 |
2 |
P53 does not activate something |
3 |
Something activates P53 |
4 |
Something interacts with CD4 |

| No. | Search time(first) |
Search time(all) |
# results |
|---|---|---|---|
1 |
0.152s |
1.271s |
8 |
2 |
0.086s |
2.265s |
11 |
3 |
0.005s |
4.251s |
578 |
4 |
0.049s |
3.971s |
111 |
We compared our system with an existing XML database, eXist. The target data are 133,375 MEDLINE abstracts with annotations which give the result of parsing. While indexing, eXist cannot construct the index of 48,095 abstracts, around 1/3 of abstracts we used, because the structure of them is to complex. Because our system used simple index structure which is the list of the position and depth for each word appearance, we can construct the index when the structure of target data is complex.
Table 6 shows the search time of the two systems for several search requests. The search requests were converted into region algebra expressions in the same way as in the previous experiment. The search requests were also converted into XQuery expressions, as shown in Table 7. Our system can retrieve results more rapidly than eXist.
| Search request | Our sytem |
eXist |
|---|---|---|
P53 activates something |
0.107s |
58.806s |
Something activates P53 |
0.104s |
58.838s |
P53(keywordのみ) |
0.015s |
11.556s |
| P53 activates something | for $s in //sentence[.//word = “p53”], |
7. Conclusions and future work
We have described a system for searching tag-annotated text based on region algebra. We improved the region algebra algorithm in order to account for nested tag structures and to incorporate variables in region algebra expressions, allowing more complex search requests. We also compared our system with an existing XML database, showing that our system can find results more quickly and is more robust.
Although our system can search regions by specifying the containment relation and and/or relation of the regions, we need more advanced operations to respond to even more complex search requests. Our system can already execute complex queries over a huge database, and in future work it can be coupled with a question answering system, to support complex searches for answers.
Reference
- Clarke, Charles L. A., Gordon V. Cormack, Forbes J. Burkowski An Algebra for Structured Text Search and A Framework for its Implementation. The Computer Journal, 38(1):43-56, 1995.
- Jaakkola, Jani and Pekka Kilpelainen Nested Text-Region Algebra. Technical Report C-1999-2, University of Helsinki, 1999.
- Boncz, Peter, Torsten Grust, Maurice van Keulen, Stefan Manegold, Jan Rittinger and Jens Teubner MonetDB/XQuery: A Fast XQuery Processor Powered by a Relational Engine. In the Proceedings of SIGMOD2006, pp. 479-490, 2006.
- Meier, Wolfgang eXist: An Open Source Native XML Database. In Web, Web-Services, and Database Systems: NODe 2002 Web- And Database-Related Workshops, 2002
- Miyao, Yusuke and Jun'ichi Tsujii. Probabilistic disambiguation models for wide-coverage HPSG parsing. In the Proceedings of ACL 2005. Ann Arbor, Michigan, pp. 83-90, June 2005.
- World Wide Web Consortium XQuery 1.0: An XML Query Language.
http://www.w3.org/TR/xquery/ - World Wide Web Consortium XML Path Language (XPath) 2.0.
http://www.w3.org/TR/xpath20/