Domain Adaptation of an HPSG Parser
1. Introduction
In this research, we present a method for adapting an HPSG parser (Ninomiya et al. 2006) trained on the WSJ section of the Penn Treebank (Marcus et al. 1994) to another domain. Our method trains a probabilistic model of lexical entry assignments to words in a target domain, and incorporates the re-trained model into the original parser. The cost for the re-training is much lower than the cost of training the entire disambiguation model from scratch.
The experimental results revealed that by simply re-training the probabilistic model of lexical entry assignments we achieve higher parsing accuracy than with a previously proposed adaptation method (Hara et al. 2005). In addition, combined with this previous method, our approach achieves accuracy as high as that obtained by re-training the original parser from scratch, but with much lower training cost.
In recent years, it has been shown that lexical information plays a very important role for high accuracy of lexicalized grammar parsing (Ninomiya et al. 2006). Our findings basically follow the above results. The contribution of this research is to provide empirical results of the relationships among domain variation, probability of lexical entry assignment, training data size, and training cost. In particular, this research empirically shows how much in-domain corpus is required for satisfactory performance.
In this section, we first introduce an HPSG parser and describe our previous method for domain adaptation. We next show our methods of re-training a lexical disambiguation model and incorporating it into the original model. We then evaluate our method through experiments on the GENIA treebank.
2. An HPSG Parser
HPSG (Pollard et al. 1994) is a syntactic theory based on lexicalized grammar formalism. In HPSG, a small number of grammar rules describe general construction rules, and a large number of lexical entries express word-specific characteristics. The structures of sentences are explained using combinations of grammar rules and lexical entries.
The HPSG parser used in this study is (Ninomiya et al. 2006), which is based on Enju (Miyao et al. 2005). Lexical entries of Enju were extracted from the Penn Treebank (Marcus et al. 1994), which consists of sentences collected from The Wall Street Journal (Miyao et al. 2004). The disambiguation model of Enju was trained on the same treebank.
The disambiguation model of Enju is based on a feature forest model (Miyao et al. 2002). The probability, pE (t | w), of producing the parse result ![]() for a given sentence w=〈w1,…,wu〉is defined as
for a given sentence w=〈w1,…,wu〉is defined as
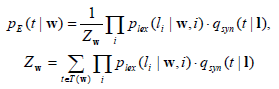
where l =〈l1,…,lu〉is a list of lexical entries assigned to w, plex (li | w, i) is a probabilistic model giving the probability that lexical entry li is assigned to word wi, qsyn (t | l) is a disambiguation model of tree construction and gives the possibility that parse candidate t is produced from lexical entries l, and T(w) is a set of parse candidates assigned to w. With a treebank of a target domain as training data, model parameters of plex and qsyn are estimated so as to maximize the log-likelihood of the training data.
We previously proposed a method for adapting an HPSG parser trained on the Penn Treebank to a biomedical domain (Hara et al. 2005). We re-trained a disambiguation model of tree construction, i.e., qsyn, for the target domain. In this method, qsyn of the original parser was used as a reference distribution (Jelinek 1998) of another disambiguation model, and the new model was trained using a treebank of a target domain. Since re-training used only a small treebank of the target domain, the cost was small and parsing accuracy was successfully improved.
3. Re-training of a Disambiguation Model of Lexical Entry Assignments
Our idea of domain adaptation is to train a disambiguation model of lexical entry assignments for the target domain and then incorporate it into the original parser. Since Enju includes the disambiguation model of lexical entry assignments as plex (li | w, i), we can implement our method in Enju by training another disambiguation model p’lex (li | w, i) of lexical entry assignments for the biomedical domain, and then replacing the original plex (li | w, i) with the newly trained p’lex (li | w, i).
In this paper, for p’lex (li | w, i), we train a disambiguation model plex-mix (li | w, i) of lexical entry assignments. plex-mix (li | w, i) is a maximum entropy model and the feature functions for it is the same as plex (li | w, i). With these feature functions, we train plex-mix (li | w, i) by using the treebanks both of the biomedical domain and the original domain.
In the experiments, we implement the above approach and examine the contribution of our method to parsing accuracy. In addition, we implemented several other intuitive or previous methods and compared the performance of the obtained models with our approach. The implemented methods are as follows.
baseline: using the original model of Enju
GENIA only: executing the same method used for training the disambiguation model of Enju, only on the GENIA Treebank
Mixture: executing the same method used for training the disambiguation model of Enju, both on the Penn Treebank and the GENIA Treebank
HMT05: our previous approach (Hara et al. 2005)
Our method: replacing plex of the original model with plex-mix, while leaving qsyn as it is
Our method + HMT05: replacing plex of the original model with plex-mix and also replacing qsyn with the model re-trained by our previous method (Hara et al. 2005) (the combination of our method and the "HMT05" method)
4. Experiments with the GENIA Corpus
We implemented the models shown above, and then evaluated their performance. The original parser, Enju, was developed on Section 02-21 of the Penn Treebank (39,832 sentences) (Ninomiya et al. 2006). For the training of those models, we used the GENIA treebank (Kim et al. 2003), which consists of 1,200 abstracts (10,848 sentences) extracted from MEDLINE. We divided the GENIA treebank into three sets of 900, 150, and 150 abstracts (8,127, 1,361, and 1,360 sentences), and these sets were used respectively as training, development, and final evaluation data.
In the following experiments, we measured the accuracy of predicate-argument dependencies on the evaluation set. The measure is labeled precision/recall (LP/LR), which is the same measure as the previous work (Ninomiya et al. 2006). In the evaluation of the given models, we focused mainly on the accuracy against the cost, and measured the accuracy variations according to the size of the GENIA treebank for training and according to the training time. We changed the size of the GENIA treebank for training: 100, 200, 300, 400, 500, 600, 700, 800, and 900 abstracts. Figures 1 and 2 show the F-score transition according to the size of the training set and the training time among the given models respectively. Table 1 shows the parsing accuracy and the training time which were obtained when using 900 abstracts. Note that Figure 2 does not include the results of the "Mixture" method because only the method took too much training cost as shown in Table 1.
Without re-training the model, Enju gave the parsing accuracy of 86.39 in F-score, which was 3.42 point lower than the one Enju gave for the original domain, the Penn Treebank. This is the baseline accuracy of the experiments. The "Mixture" method could obtain the highest level of the parsing accuracy for any size of the GENIA treebank while it required too much training cost. We would like to obtain the accuracy at least as high as the method, with as low cost as possible.
Our method could constantly give higher accuracy than the "baseline," "GENIA only," and even than "HMT05" methods. These results would indicate that, for an individual method, re-training a model of lexical entry assignments might be more critical to domain adaptation than re-training that of tree construction. In addition, for so far as the small treebank goes, our method could give as high accuracy as the "Mixture" method with much lower training cost. Our method would be a very satisfactory approach when applied with a small treebank.
The "Our method + HMT05" model gave equally high parsing accuracy as the "Mixture" model for any size of the training corpus. In particular, for the maximum size of the training corpus, the "Our method + HMT05" model gave even higher parsing accuracy than the "Mixture" method. This difference was shown to be significant according to stratified shuffling test with p-value < 0.10, which might suggest the beneficial impact of the "Our method + HMT05" method. In addition, Figure 2 and Table 1 shows that training with the "Our method + HMT05" method required much less time than training the "Mixture" model. According to the above observations, we would be able to say that the "Our method + HMT05" method might be the most ideal among the given methods. Figure 1 showed that 6,500 sentences would be sufficient for achieving as high parsing accuracy as the baseline for the original domain (see "baseline (for PTB)" in Table 1).
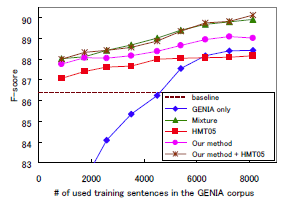 Figure 1. Corpus size vs. accuracy
Figure 1. Corpus size vs. accuracy 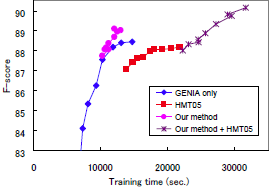 Figure 2. Training time vs. accuracy
Figure 2. Training time vs. accuracy
|
F-score |
Training time(sec.) |
|---|---|---|
baseline(for PTB) |
89.81 |
0 |
Baseline |
86.39 |
0 |
GENIA only |
88.45 |
14,695 |
Mixture |
89.94 |
238,576 |
HMT05 |
88.18 |
21,833 |
Our method |
89.04 |
12,957 |
Our method + HMT05 |
90.15 |
31,637 |
5. Conclusion and Future Direction
This research presents an effective approach to adapting an HPSG parser trained on the Penn Treebank to a biomedical domain. We trained a probabilistic model of lexical entry assignments in the target domain and then incorporated it into the original parser. The experimental results showed that this approach obtains higher parsing accuracy than our previous approach of adapting the structural model alone. Moreover, the results showed that the combination of our method and our previous approach could achieve parsing accuracy that is as high as the accuracy obtained by re-training an HPSG parser for the target domain from scratch, but with much lower training cost. With this model, the parsing accuracy for the target domain improved by 3.84 f-score points, using a target treebank of 8,127 sentences. Experiments showed that 6,500 sentences are sufficient for achieving as high parsing accuracy as the baseline for the original domain.
In future work, we would like to explore further performance improvement of our approach. For the first step, domain-specific features such as named entities could be very helpful for dealing with technical terms in a target domain.
References
- Hara Tadayoshi, Miyao Yusuke, and Tsujii Jun’ichi, Adapting a probabilistic disambiguation model of an HPSG parser to a new domain, In the Proceedings of IJCNLP 2005, Jeju Island, Korea, pp. 199-210, October 2005.
- Jelinek Frederick, Statistical Methods for Speech Recognition, The MIT Press, 1998.
- Kim Jing-Dong, Ohta Tomoko, Tateishi Yuka, and Tsujii Jun’ichi, GENIA corpus – a semantically annotated corpus for bio-textmining, Journal of Bioinformatics, 19(suppl. 1):i180-i182, 2003.
- Marcus Mitchel, Kim Grace, Marcinkiewicz Mary Ann., MacIntyre Robert, Bies Ann, Ferguson Mark, Katz Karen, and Schasberger Britta, The Penn Treebank: Annotating predicate argument structure, In the Proceedings of the Human Language Technology Workshop, San Francisco, CA, 1994.,
- Miyao Yusuke, Ninomiya Takashi, and Tsujii Jun’ichi, Corpus-oriented grammar development for acquiring a Head-driven Phrase Structure Grammar from the Penn Treebank, In the Proceedings of IJCNLP 2004, Hainan Island, China, pp.684-693, 2004.
- Miyao Yusuke and Tsujii Jun’ichi, Maximum entropy estimation for feature forests, In the Proceedings of HLT 2002, March 2002.
- Miyao Yusuke and Tsujii Jun’ichi, Probabilistic disambiguation models for wide-coverage HPSG parsing, In the Proceedings of ACL 2005, Ann Arbor, Michigan, pp. 83-90, June 2005.
- Ninomiya Takashi, Matsuzaki Takuya, Tsuruoka Yoshimasa, Miyao Yusuke, and Tsujii Jun’ichi, Extremely lexicalized models for accurate and fast HPSG parsing, In the Proceedings of EMNLP 2006, Sydney, Australia, pp. 155-163, July 2006.
- Pollard Carl and Sag Ivan A., Head-Driven Phrase Structure Grammar, University of Chicago Press, 1994.