GENIA Corpus
1. Introduction
In literature, information is mainly written in a natural language, which means the information is not directly accessible to computers. It is a general expectation that the better a computer can decode a language, the better it can access the information which is encoded in the language. With this background, application of natural language processing (NLP) technology is becoming more and more popular for text mining (TM) from biomedical literature.
In recent decades, text corpora have been in the center of NLP research. A corpus is a large collection of texts which is often intended to represent a certain domain or style of texts or language expressions. In NLP, text annotation often means attaching a computable interpretation to texts, providing computers with direct access to desired information which is aligned to relevant text pieces. It has been many times observed that a well-created corpus with annotations establishes or promotes research in NLP, IR or IE, providing reference materials for the development of computational systems (Penn Treebank)(MUC data sets)(TREC data sets).
The GENIA corpus is a collection of Medline abstracts which is intended to represent the literature of molecular biology. The main value of the corpus comes from annotations made to the corpus at various levels. These GENIA annotations have contributed to the community by providing reference materials, and many works based on the resource have been reported.
GENIA annotation has been done from two perspectives; to make the biomedical knowledge encoded in the text transparent (semantic annotation), and to reveal the syntactic structure behind the text (linguistic annotation).
2. Linguistic Annotation
Although the linguistic structure of text, such as the phrasal or dependency structure, may not be the main interest of text mining practitioners, it is often studied by text mining researchers to improve their systems. It is generally accepted that information about the linguistic structure of text is helpful in accessing the information encoded in the text. Knowing about the linguistic structure of text is like having a map, perhaps not complete, of a mine’s topography, showing paths and suggesting potential places to dig for pieces of knowledge.
Tokenization and POS labeling are often regarded as the first steps of NLP processing. These steps determine the basic units of a sentence and their properties, e.g., grammatical or syntactic identity. Figure 1 shows an example of a sentence which has been tokenized and POS-labeled. Note that punctuation and parentheses are usually split from adjoining words to make separate tokens.
 Figure 1. A sentence with part-of-speech annotation
Figure 1. A sentence with part-of-speech annotationWe have annotated 1,999 Medline abstracts with 42 part-of-speech labels according to Penn Treebank POS tagging scheme which is a de-facto standard. Tsuruoka et al (2005) reported that they could improve part-of-speech tagging accuracy on Medline text from 91.6% to 98.5% by using the Part-of-speech-annotated GENIA corpus as training material.
Training corpus | Test corpus | |
|---|---|---|
WSJ | GENIA | |
WSJ | 97.2% |
91.6% |
WSJ + GENIA | 97.2% |
98.5% |
Syntactic analysis reveals how words in a sentence are organized to form the meaning of the sentence. In a sentence, words may be grouped together into phrases. Similarly, phrases together with or without other words may also be grouped to form larger phrases. This process may continue until eventually the whole sentence is grouped together, yielding a tree structure of phrases with the root element covering the whole sentence, internal elements corresponding to phrases and leaf elements corresponding to words.
Figure 2 shows a sentence annotated for syntactic structures.
 Figure 2. A sentence with syntactic tree annotation
Figure 2. A sentence with syntactic tree annotationWe have annotated 1,200 Medline abstracts with their parse trees. Generally we tried to follow Penn Treebank II (PTB) bracketing guidelines (Beis et al, 1995) which is a de facto standard. Hara et al (2005) reported that they could improve the parsing performance of an HPSG parser from f-score of 85.1% to 86.9%.
3. Semantic Annotation
Biological entities like proteins or genes are the most fundamental structures of interest in biomedical research, and detecting mention of such entities in texts is considered crucial to accessing useful information. In GENIA, biological entities are annotated during the process of term annotation, which covers technical terms from biology including entity names. The definition and classification of such terms comes from the GENIA ontology.
Figure 3 shows a sentence annotated for terms. For example, the text span “Mice” is annotated as a multi cell organism (“Multi_cell”). Term annotations may be recursive. For example, the three text spans, “human T cell leukemia virus”, “HTLV-1” and “Tax”, are annotated as terms inside a bigger text span, “human T cell leukemia virus (HTLV-1) Tax gene”, which is also annotated as a term.
The GENIA term annotation is grounded on the GENIA ontology which defines biomedically meaningful nominal concepts. Figure 4 shows the GENIA ontology, where concepts are classified in a hierarchy. Note that the terminal concepts are presented in bold boxes. They define the terms that need to be identified from the literature and thus become the target of annotation. The numbers appearing next to the labels of terminal concepts indicate their frequency in the GENIA corpus version 3.01.
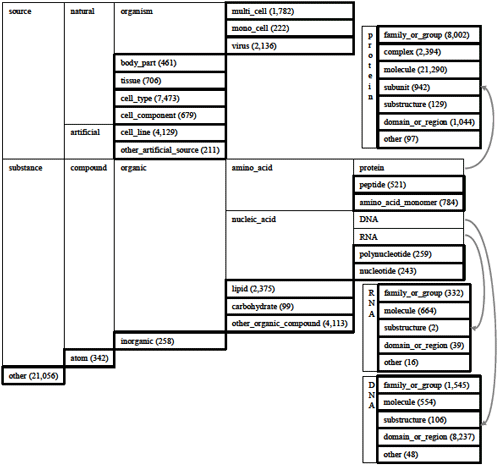 Figure 4. The hierarchy of GENIA ontology
Figure 4. The hierarchy of GENIA ontology1,999 Medline abstracts have been annotated with term labels defined in the GENIA ontology. The GENIA term-annotated corpus is now widely used as one of the de facto standards of bio-entity-annotation. Table 2 lists some state-of-the-art systems of bio-entity recognition which are trained using the GENIA term-annotated corpus.
Bio-entity recognition system | Recall | Precision | F-score |
|---|---|---|---|
SVM+HMM (Zhou et al., 2004) |
76.0 |
69.4 |
72.6 |
Semi-Markov CRFs (in prep.) |
72.7 |
70.4 |
71.5 |
Two-Phase (Kim et al., 2005) |
72.8 |
69.7 |
71.2 |
Sliding Window (in prep.) |
71.5 |
70.2 |
70.8 |
CRF (Settles, 2005) |
72.0 |
69.1 |
70.5 |
MEMM (Finkel et al, 2004) |
71.6 |
68.6 |
70.1 |
| ... | ... | ... | ... |
4. Conclusion and Fiture Directions
The GENIA corpus has been annotated for part-of-speech, syntactic tree and biomedical terms. The corpus together with the rich annotation is used by many researchers and practitioners in the bio-text mining community, and many state-of-the-art IE systems have been developed by making use of it as reference material.
Future work includes extending the scope of the corpus to include full papers, as we believe more serious knowledge could be found from full papers than from abstracts.
References
- Tateisi, Yuka and Jun'ichi Tsujii. Part-of-Speech Annotation of Biology Research Abstracts. In the Proceedings of 4th International Conference on Language Resource and Evaluation (LREC2004). IV. Lisbon, Portugal, pp. 1267-1270, May 2004.
- Tsuruoka, Yoshimasa, Yuka Tateishi, Jin-Dong Kim, Tomoko Ohta, John McNaught, Sophia Ananiadou and Jun'ichi Tsujii. Developing a Robust Part-of-Speech Tagger for Biomedical Text. In the Advances in Informatics - 10th Panhellenic Conference on Informatics. LNCS 3746. Volos, Greece, pp. 382--392, November 2005. ISSN 0302-9743.
- Tateisi, Yuka, Akane Yakushiji, Tomoko Ohta and Jun’ichi Tsujii . Syntax Annotation for the GENIA corpus. In the Proceedings of the IJCNLP 2005, Companion volume. Jeju Island, Korea, pp. 222--227, October 2005.
- Hara, Tadayoshi, Yusuke Miyao and Jun'ichi Tsujii. Adapting a probabilistic disambiguation model of an HPSG parser to a new domain. In Robert Dale, Kam-Fai Wong, Jian Su and Oi Yee Kwong (Eds.), Natural Language Processing – IJCNLP 2005. Lecture Notes in Artificial Intelligence3651. Jeju Island, Korea, pp. 199--210, Springer-Verlag, October 2005. ISSN 0302-9743.
- Kim, Jin-Dong, Tomoko Ohta, Yuka Teteisi and Jun'ichi Tsujii. GENIA corpus - a semantically annotated corpus for bio-textmining. Bioinformatics. 19(suppl. 1). pp. i180-i182, Oxford University Press, 2003. ISSN 1367-4803.
- Kim, Jin-Dong, Tomoko Ohta, Yoshimasa Tsuruoka, Yuka Tateisi and Nigel Collier. Introduction to the Bio-Entity Recognition Task at JNLPBA. In the Proceedings of the International Workshop on Natural Language Processing in Biomedicine and its Applications (JNLPBA-04). Geneva, Switzerland, pp. 70--75, 2004.
- Ohta, Tomoko, Yusuke Miyao, Takashi Ninomiya, Yoshimasa Tsuruoka, Akane Yakushiji, Katsuya Masuda, Jumpei Takeuchi, Kazuhiro Yoshida, Tadayoshi Hara, Jin-Dong Kim, Yuka Tateisi and Jun'ichi Tsujii. An Intelligent Search Engine and GUI-based Efficient MEDLINE Search Tool Based on Deep Syntactic Parsing. In the Proceedings of the COLING/ACL 2006 Interactive Presentation Sessions. Sydney, Australia, pp. 17--20, July 2006.