Domain Adaptation of Part-of-speech Taggers
1. Introduction
Part-of-speech (POS) tagging is a useful and important step of analysis in natural language processing. POS tags are directly used for many tasks including lemmatization and pattern-based information extraction, and a variety of higher level analyses such as named entity recognition and parsing use the information about POS tags as part of the input (Okanohara et al., 2006; Yoshida et al., 2007). It is, therefore, important to have an accurate POS tagger for the documents that one is going to analyze.
Previous studies have shown that one can build an accurate POS tagger by taking the supervised machine learning approach. State-of-the-art learning algorithms include cyclic dependency networks (Toutanova et al., 2003), support vector machines (Gimenez and Marquez, 2004), and bidirectional maximum entropy (Tsuruoka and Tsujii, 2005). One can achieve an accuracy over 97% on the Wall Street Journal (WSJ) corpus by using one of these algorithms.
The weakness of the supervised learning approach is that we need to create training data, which requires a large amount of manual work. This is not an issue when we are going to deal with documents that are similar to the ones for which annotated training data are already available (e.g. newswire), because the tagger trained on the existing data will perform reasonably well on the new domain as well. However, when the target domain is distant from the domain on which the tagger is trained (e.g. biology vs. newswire), the performance of the tagger can be very poor. Consequently, we still need to create training data manually in many practical situations.
In this work, we investigate techniques for reducing the amount of training data needed for achieving a reasonable level of accuracy.
2. POS tagging with CRFs
As the learning framework of POS tagging, we adopt conditional random fields (CRFs) proposed by Lafferty et al. (2001). CRFs have good properties for POS tagging. Firstly, the decoding cost is very low. Although a little computational time is required to identify active features before the decoding process, the decoding cost for first-order CRFs is basically equivalent to that for first-order HMMs, which makes it easy to build a fast tagger. Secondly, CRFs can output probabilistic confidence of tagging for individual tokens. This is straight-forward because the forward-backward decoding automatically gives us marginal probabilities for each state. N-best sequences can also be obtained in a principled manner. These types of probabilistic information have been shown to be useful in subsequent processes like parsing (Yoshida et al., 2007). Lastly, but most importantly, CRFs give a state-of-the-art tagging accuracy.
3. Using Generative Models
Generative models such as HMMs have the advantage that we can make use of unlabeled data in a principled way using the EM algorithm. Kazama et al. (2001) proposed a simple approach to combining the merits of discriminative and generative models. The core idea is to use the output of the generative model trained with the EM algorithm as a feature for the discriminative model.
We train a HMM with the Baum-Welch algorithm using unlabeled data. Once we have trained the HMM, we perform Viterbi decoding for each sentence and use each hidden state obtained as a state feature for the CRF.
4. Active Learning
Another way of reducing the quantity of training data is to change the sampling strategy for creating annotated data. Unlike the standard random sampling-based method, active learning algorithms tell the annotator which samples should be annotated first, considering the informativeness of the samples.
In this work we use a variant of the uncertainty sampling heuristic presented by (Lewis and Gale,
1994). The learning process is as follows.
- Create an initial tagger with k randomly-sampled sentences.
- Apply the current tagger to each sentence.
- Find the k sentences for which the tagger is least certain in terms of the average value of tag probabilities.
- Annotate the subsample of k sentences.
- Train a new tagger on all annotated sentences.
- Go back to 2.
5. Domain Adaptation
In the previous sections we have described the techniques for reducing training data when we train a tagger from scratch. However, in practice, a more common situation would be that one has training data for “standard” English (e.g. WSJ) but needs to develop a tagger for a different domain (e.g. biology). In those situations, we can assume the existence of large annotated data for the source domain (i.e. WSJ), and the goal is to minimize the training data for the new domain (i.e. biology).
We take an approach used in previous work for domain adaptation. First, we build a tagger using the training data for the source domain. We then use the output of this tagger as a feature for machine learning when we train a tagger for the new domain. By taking this approach, we can concentrate on the training data for the new domain, and afford to perform active learning in a realistic time
6. Experiments
We carried out several sets of experiments to evaluate the techniques described in the previous sections. We took the biomedical domain as the target domain for the experiments of domain adaptation, since two large annotated corpora (GENIA and PennBioIE) are available.
Figure 5.1 shows the learning curves evaluated on the WSJ corpus. The x-axis is the number of tokens used in training, and the y-axis is the accuracy evaluated on the test set. The figure contains three learning curves. The first curve (Random) shows the performance achieved by the normal training procedure where HMMs are not used and training samples are provided by random sampling. The second curve (Random + HMM) shows the case where we added the features produced by the unsupervised HMM. The third curve (Active Learning + HMM) shows the performance achieved by using the active learning method together with the features provided by the unsupervised HMM.
Active learning was very effective. The merit of active learning becomes more evident as the amount of training data increases. The accuracy achieved by active learning with the training data of 100,000 tokens was 96.71. This is a good accuracy, considering the fact that 100,000 tokens are only one-ninth of the entire training data.
Figure 5.2 shows the learning curves evaluated on the GENIA corpus. The features produced by the unsupervised HMM were not as effective as in the case of WSJ. On the other hand, the features produced by the WSJ-trained tagger significantly improved the accuracy when the amount of training data is small (< 10, 000 tokens). Active learning has shown a remarkable effect. Active learning enabled us to achieve almost the upper-bound accuracy with only 100,000 tokens of training data. Table 5 summarizes the amount of training data and the accuracy achieved with this active learning setting. The annotation of 3,200 sentences enables us to achieve 98.40% accuracy, while the upper-bound is 98.58%.
Figure 5.3 shows the experimental results on the PennBioIE corpus. We can see the same trend, but the unsupervised HMM was more helpful than on GENIA. Again, the active learning method enabled us to achieve an almost upper-bound accuracy (97.66%) with only one-fifth of the entire corpus.
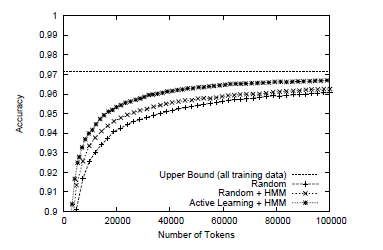 Figure 5.1 Learning curves on the Wall Street Journal corpus.
Figure 5.1 Learning curves on the Wall Street Journal corpus.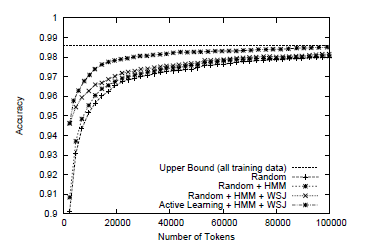 Figure 5.2 Learning curves on the GENIA corpus.
Figure 5.2 Learning curves on the GENIA corpus.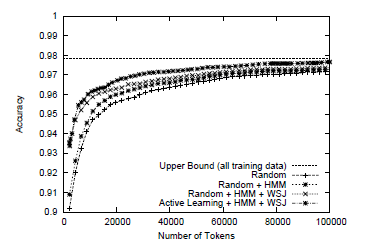 Figure 5.3 Learning curves on the PennBioIE corpus.
Figure 5.3 Learning curves on the PennBioIE corpus.7. Conclusion
We have shown that the combination of the use of a generative model, a WSJ-trained tagger and active learning can drastically reduce the amount of annotated data needed to develop an accurate POS tagger for a new domain. Experimental results revealed that we can build very accurate taggers (98.40% on GENIA and 97.66% on PennBioIE) with only several thousand annotated sentences.
We took the task of POS tagging as the target, but CRFs are also effective in other tasks such as named entity recognition and shallow parsing. The application of the techniques described in this work to such tasks is an interesting topic for future work.
References
- Yoshida, Kazuhiro, Yoshimasa Tsuruoka, Yusuke Miyao, and Jun'ichi Tsujii. Ambiguous Part-of-Speech Tagging for Improving Accuracy and Domain Portability of Syntactic Parsers. In the Proceedings of IJCAI-07, pp. 1783-1788, 2007.
- Okanohara, Daisuke, Yusuke Miyao, Yoshimasa Tsuruoka, and Jun'ichi Tsujii. Improving the Scalability of Semi-Markov Conditional Random Fields for Named Entity Recognition. In the Proceedings of COLING/ACL 2006, pp. 462-472, 2006.
- Tsuruoka, Yoshimasa and Jun'ichi Tsujii. Bidirectional Inference with the Easiest-First Strategy for Tagging Sequence Data. In the Proceedings of HLT/EMNLP 2005. Vancouver, pp. 467-474, 2005.
- Kazama, Jun’ichi, Yusuke Miyao, and Jun'ichi Tsujii. A Maximum Entropy Tagger with Unsupervised Hidden Markov Models. In the Proceedings of NLPRS 2001, pp. 333-340, 2001.
- Toutanova, Kristina, Dan Klein, Christopher Manning and Yoram Singer. Feature-rich part-of-speech tagging with a cyclic dependency network. In the Proceedings of HLT-NAACL 2003, pp. 252-259, 2003.
- Gimenez, Jesus, and Lluis Marquez. SVMTool: A general pos tagger generator based on support vector machines. In the Proceedings of LREC 2004, 2004.