
HIMERA (HIStory of MEdicine coRpus Annotation)
Description
The HIMERA annotated corpus contains a set of published historical medical documents that has been manually annotated with semantic information that relevant to the study of medical history and public health. Specifically, annotations correspond to seven different entity types and two different event types (which encode relationships amongst entities), chosen based on extensive discussions with medical historians.
HIMERA is intended to provide the means to train and evaluate text mining (TM) tools that are able to recognise relevant entities and relationships (or events) that hold between them, in a range of types of published medical documents, dating from the mid 19th century onwards.
Availability
- Download - The corpus may be downloaded for research purposes (please observe the terms of the licence below). The format of the annotations is described on a separate page.
- Visualisation - a graphical visualisation of the annotated corpus is available online, using the brat annotation editing/viewing software
Motivation
TM tools used to extract relevant semantic information (e.g., entities and events) automatically from collections of documents are often reliant of the availability of annotated corpora, i.e., subsets of the complete document collection, in which the semantic information of interest has been manually annotated by domain experts. The annotated documents are used to train the tools (using machine learning (ML) methods to recognise the target semantic information in previously unseen documents. The output tools can be used, e.g., in the development of semantic search systems, that can aid in the efficiency and effectiveness of researchers' searches.
The semantic information that is annotated varies between subject areas and/or the specific interests of researchers. In our case, annotation categories have been chosen that are relevant from medical/public health and historical perspectives.
The composition of documents in HIMERA has been carefully chosen, based on the fact that ML systems are usually highly sensitive to the features of the text on which they are trained. Our aim is to facilitate the semantic exploraation of documents of various types published over a wide time span. This means that, in order to train robust TM tools, our annotated corpus needs to take account of the fact that over time, concepts, the ways used to refer to them and language usage in general, are subject to change. HIMERA therefore provides evidence of the differing ways in which concepts are mentioned, and relationships between them are expressed, in a range of document types, representing different writing styles and/or focus, and from a range of different time periods from the mid 19th century onwards.
Annotation Scheme
The annotated entity types, together with brief descriptions, are provided in Table 1.
| Entity Type | Description | Examples |
|---|---|---|
| Condition | Medical condition/ailment | phthisis, bronchitis, typhus |
| Sign_or_Symptom | Altered physical appearance/behaviour as probable result of injury/condition | cough, pain, rise in temperature, swollen |
| Anatomical | Entity forming part of human body, including substances and abnormal alterations to bodily structures | lung, lobe, sputum, fibroid |
| Subject | Individual or group under discussion | children, asthma patients, those with negative reactions to tuberculin |
| Therapeutic_or_ Investigational | Treatment/intervention administered to combat condition (including diet/foodstuffs), or substance, medium or procedure used in investigational medical or public health context | atrophine sulphate, generous diet, change of air, lobectomy |
| Biological Entity | Living entity not part of human body, including microorganisms, animals and insects | tubercle bacilli, mould, guinea-pig, flea |
| Environmental | Environmental factor relevant to incidence/prevention/control/treatment of condition. Includes climatic conditions, foodstuffs, infrastructure, household items or occupations whose environmental factors are mentioned | humidity, high mountain climates, infected milk, linen, drains, sewers, dusty occupations |
Events are annotated as follows:
- A word or phrase that characterises the relationship is determined and annotated. This annotation, called the event trigger, frequently corresponds to a verb (e.g., caused) or a nominalisation (e.g., affect).
- The trigger is assigned an event type, to encode the nature of the relationship annotated.
- A set of participants (in the same sentence as the event trigger) is identified, which contribute towards the description of the event. Participants may be entities, or previously annotated events.
- Each participant is assigned a semantic role, according to the type of information that it contributes towards the overall description of the event
Table 2 provides definitions of the two event types annotated in HIMERA, along with descriptions of the possible participant types and their corresponding semantic roles.
| Event Type | Description | Possible Participants/Semantic roles |
|---|---|---|
| Affect | A (previously existing) entity or event is affected, infected, undergoes change or is transformed, possibly by another entity or event | Cause: Cause of the affection |
| Target: Entity or event affected | ||
| Subj: Individual or group affected | ||
| Causality | An entity or event results in the manifestation of a (previously non-existing) entity or event | Cause: Cause of the manifestation |
| Result: New entity or event that manifests itself | ||
| Subj: Individual or group associated with the event |
Some examples of annotated Affect and Causality events (as dislayed by brat) are shown in Figures 1 and 2. Entities are shown in green and event triggers are shown in blue. Arrows from the triggers are used to indicate links betwen events triggers and event participants. Labels on the arrows indicate the semantic roles assigned.
 Fig 1. - Example Affect Events.
Fig 1. - Example Affect Events.
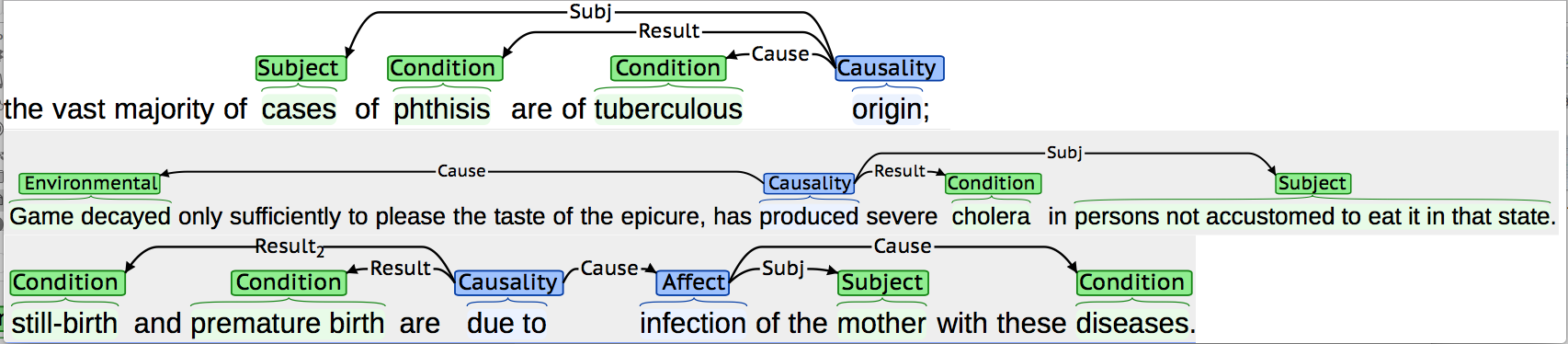 Fig 2. - Example Causality Events.
Fig 2. - Example Causality Events.
Features to note from these figures include the following:
- Different events can have differing numbers of participants, depending on the information present in the sentence; it is not necessary for all three participant types to be annotated for each event.
- The same semantic role may be assigned to multiple participants.
- Events may be negated, e.g., it may be specified in the text that the event did not happen. In this case, a Negation Cue will normally be identified, and linked to the event in the same way as participants.
- Event participants may themselves be events.
HIMERA composition
HIMERA includes documents from two large and diverse archives of published historical medical text, each of which represents different points of view on medical matters, and has different target audiences. Brief details of these archives are as follows:
- The British Medical Journal (BMJ) is aimed at medical professionals, and includes various types of articles, including research, analysis, practice, case reports, letters, and obituaries. The archive includes articles from 1840 onwards.
- The London area Medical Officer of Health (MOH) reports, digitised by the Wellcome Library, are concerned with examining public health issues in different London boroughs. The archive consists of around 5,000 reports produced between 1848 and 1972, whose lengths range from a few pages to several hundred pages.
HIMERA has the following features:
- Most documents cover lung diseases, based upon advice from our advisory board about the significance of studying them over long periods of time.
- It consists of 35 articles from the BMJ and 4 excepts from MOH reports.
- BMJ articles are representative of the variety of article types, including letters, case reports and leading articles
- Documents were chosen from four key decades in medical history: 1850s, 1890s, 1920s and 1960s.
Evaluation
Approximately a quarter of the corpus was double annotated to allow inter-annotator agreement (IAA) rates to be calculated, and to ensure the consistency of the annotations. We calculated IAA in terms of F-Score, and found that high levels of agreement were acheived. For exact span matches (i.e., where the start and end of the annotated text spans chosen by both annotators must match exactly), the IAA was 0.80 F-Score. For relaxed matches, where it is sufficient for the annotations to include some common parts, the IAA was 0.86 F-Score.
Acknowledgements
The HIMERA corpus was created as part of the AHRC-funded "Mining the History of Medicine" project (Grant No. AH/L00982X/1). We would like to thank the BMJ for granting access to their archive of articles, and the Wellcome Trust, for consenting to our use of the MOH reports.HIMERA corpus licence
1. Copyright of BMJ articles
Permission to use the 35 BMJ articles in the HIMERA corpus for TM research purposes has been granted by the BMJ. Pleaase attribute the BMJ if you use the HIMERA corpus.
2. Copyright of MOH reports
The MOH reports, provided by the Wellcome Trust, are licensed under a Creative Commons licence (CC-BY 4.0).
3. Copyright of entity and event annotations

The entity and event annotations in the HIMERA corpus were created at the National Centre for Text Mining (NaCTeM), School of Computer Science, University of Manchester, UK. They are licensed under a Creative Commons Attribution 4.0 International License. Please attribute NaCTeM when using the corpus, and please cite the following article:
Paul Thompson, Riza Theresa Batista-Navarro, Georgios Kontonatsios, Jacob Carter, Elizabeth Toon, John McNaught, Carsten Timmermann, Michael Worboys and Sophia Ananiadou (2016). Text Mining the History of Medicine. PLOS ONE, 11(1): e0144717.
Featured News
- 1st Workshop on Misinformation Detection in the Era of LLMs - Presentation slides now available
- Prof. Ananiadou appointed Deputy Director of the Christabel Pankhurst Institute
- ELLIS Workshop on Misinformation Detection - Presentation slides now available
- Prof. Sophia Ananiadou accepted as an ELLIS fellow
- BioNLP 2025 and Shared Tasks accepted for co-location at ACL 2025
- Prof. Junichi Tsujii honoured as Person of Cultural Merit in Japan
![]() Featured News Feed
Featured News Feed
Other News & Events
- AI for Research: How Can AI Disrupt the Research Process?
- CL4Health @ NAACL 2025 - Extended submission deadline - 04/02/2025
- Invited talk at the 15th Marbach Castle Drug-Drug Interaction Workshop
- Participation in panel at Cyber Greece 2024 Conference, Athens
- Shared Task on Financial Misinformation Detection at FinNLP-FNP-LLMFinLegal
![]() Other News Feed
Other News Feed


![]()




