
Biomedical Text Mining for Chinese
This page describes tools and resources developed at NaCTeM to aid with the processing of biomedical text in the Chinese language.
Chinese Biomedical Term Extraction
NaCTeM's TerMine service has been adapted to handle the extraction of terms from Chinese biomedical text. This adaptation consists of the sequential application of two pre-processing steps prior to running the existing TerMine service. Firstly, an open-source newswire-domain Chinese POS tagger, i.e., the FudanNLP POS tagger is applied to the Chinese text, followed by a set of processing rules, which are designed both to correct incorrect segmentation of the Chinese text into individual words and to correct POS-tagging errors. The Chinese biomedical term extraction workflow is shown in Figure 1.
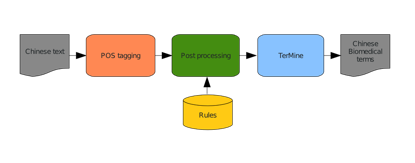 Figure 1: Chinese biomedical term extraction workflow
Figure 1: Chinese biomedical term extraction workflow
The workflow has been made available as a web service, which has already been used by Socrates.md to develop a biomedical information retrieval system. A demo of the biomedical term extraction web service will be available on this page shortly.
[DEMO COMING SOON]
MMeSH Ontology
The Mandarin Medical Subject Headings (MMeSH) [1, 2, 3] is a Chinese-English bilingual ontology consisting of two components: vocabulary and tree structure. The vocabulary includes Medical Subject Headings' (MeSH) heading terms, MeSH entry terms and Chinese synonyms; the tree structure is the same as the original MeSH tree. The version of MeSH used to construct the MMeSH Tree is MeSH 2008. The MMeSH Tree, containing a total of 369,028 terms, has the following features:- Bilingual. Each tree node has English and Chinese terms, which are aligned using heading terms.
- Heading terms. Each English heading term has an equivalent Chinese heading term, aligned via tree node number.
- Entry terms. 132,108 entry terms, which are English terms from MeSH vocabulary, are added to the MMeSH Tree and organised in terms of their heading terms.
- Synonymous terms. 188,478 synonymous terms, most of which are Chinese term, are automatically extracted from online texts and involved in the MMeSH Tree.
- Term weights. Each Chinese term (including heading term and synonyms) is assigned a term weight, which is computed based on the frequency of the term and the frequency of its English heading term.
Figure 2 illustrates an example of a tree node in MMeSH.
 Figure 2: MMeSH tree node example
Figure 2: MMeSH tree node example
The MMeSH ontoglogy has been used to facilitate query expansion in a Chinese-English biomedical cross-lingual information retrieval [2, 3].
People
Principal Investigator: Prof. Sophia Ananiadou
Researcher: Dr Xinkai Wang
Dr. Xinkai Wang obtained his PhD degree at the University of Manchester in January 2012. His research areas are cross-lingual information retrieval on Chinese biomedicine and Chinese biomedical term extraction. He is currently working as consultant on the Socrates' project.
Publications
1. Xinkai Wang and Sophia Ananiadou. A Task-Oriented Extension of Chinese MeSH Concepts Hierarchy. In Proceedings of the 2nd Workshop on Building and Evaluating Resources for Biomedical Text Mining, pages 23-30, Malta, 2010.2. Xinkai Wang, Paul Thompson, Sophia Ananiadou. Biomedical Chinese-English Clir Using an Extended CMeSH Resource to Expand Queries. In Proceedings of the Eighth International Conference on Language Resources and Evaluation (LREC 2012), pages 1148-1155, 2012
3. Xinkai Wang. Chinese-English Cross-Lingual Information Retrieval in Biomedicine Using Ontology-Based Query Expansion. PhD thesis, University of Manchester, 2012.
Featured News
- 1st Workshop on Misinformation Detection in the Era of LLMs - Presentation slides now available
- Prof. Ananiadou appointed Deputy Director of the Christabel Pankhurst Institute
- ELLIS Workshop on Misinformation Detection - Presentation slides now available
- Prof. Sophia Ananiadou accepted as an ELLIS fellow
- BioNLP 2025 and Shared Tasks accepted for co-location at ACL 2025
- Prof. Junichi Tsujii honoured as Person of Cultural Merit in Japan
![]() Featured News Feed
Featured News Feed
Other News & Events
- AI for Research: How Can AI Disrupt the Research Process?
- CL4Health @ NAACL 2025 - Extended submission deadline - 04/02/2025
- Invited talk at the 15th Marbach Castle Drug-Drug Interaction Workshop
- Participation in panel at Cyber Greece 2024 Conference, Athens
- Shared Task on Financial Misinformation Detection at FinNLP-FNP-LLMFinLegal
![]() Other News Feed
Other News Feed


![]()




