
Open Mining Infrastructure for Text and Data (OpenMinTeD)
Background
The Open Mining Infrastructure for Text and Data (OpenMinTeD) project seeks to develop an interoperable text mining infrastructure that will unite the efforts of several key players in the text mining world. Crucially, this project involves the communities at the heart of using text mining with partners in the life sciences, the social sciences and scholarly communication. The project will develop an infrastructure which combines the power of several established text mining systems (including our platform, Argo). We will publish interoperability guidelines that will allow other systems to integrate with the OpenMinted platform. The broad aim of this project is to unite the efforts of text miners across Europe and the world, simultaneously promoting reusability and community uptake.
Introduction
This project is a collaboration with a number of European partners. We seek to develop a new text mining infrastructure which will draw upon the resource of numerous existing workflow systems. The project has multiple strands and aims to deliver a lot of valuable content over a three year period. At NaCTeM, we are primarily involved with the development of an open and interoperable text mining infrastructure. We are also working with the communities which the project targets to develop text mining applications built on top of the project's infrastructure.
The figure below gives an overview of the project's structure and aims. We primarily seek to bridge the gap between current text mining technologies and the communities which need them most.
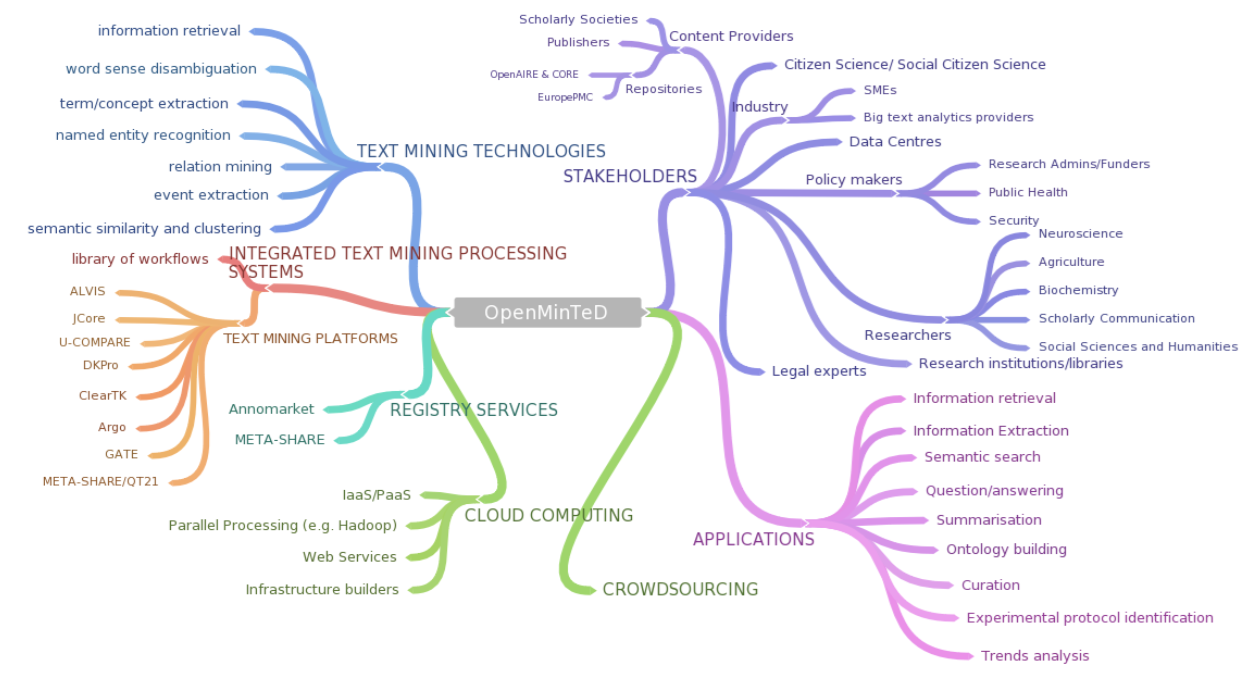
Project Aims
- Develop an open text mining infrastructure
- Develop interoperability guidelines to allow partner systems to work together for text mining purposes
- Develop community-driven applications which use the infrastructure
- Educate communities as to the benefits of text mining
- Encourage community uptake of text mining using the OpenMinTeD platform
- Examine the legal issues around licensing and text mining and make appropriate recommendations for users and policymakers
Project Team
This is a European project with 16 institutions involved as listed below. At NaCTeM, the following members of the team are engaged with OpenMinTeD:Principal Investigator: Prof. Sophia Ananiadou
Co-Investigator: Mr. John McNaught
Research Associates:
Dr. Nhung Nguyen
Funding
OpenMinted is an EC/H2020 funded project (grant id 654021). It is funded for three years starting from June 2015.
News
8th March 2018
A Text Mining and Applications Workshop, sponsored by OpenMinted and organised by the NaCTeM and the Ho Chi Minh City University of Science, will be held in Ho Chi Minh City, Vietnam, on 14th May 2018. Absttact submissions are invited.
1st March 2018
We are pleased to announce that the following paper has been accepted for presentation at LREC 2018, to be held in 7-12 May 2018, Miyazaki (Japan), from 7th - 12th May 2018. This is the first paper that reports on a corpus consisting of 200 abstracts and 100 full papers annotated with entities and relations in the biomedical domain.
Shardlow, M., Nguyen, N. T. H., Owen, G., Turner, S., O'Donovan, C., Leach, A., McNaught, J. and Ananiadou, S. (In Press). A New Corpus to Support Text Mining for the Curation of Metabolites in the ChEBI Database. In Proceedings of LREC 2018
30th November - 1st December 2017
Prof. Sophia Ananiadou will give a talk entitled Machine reading for cancer biology at the Global Pharma R&D Informatics Congress in Lisbon, Portugal.
Partner Institutions
- Athena Research and Innovation Centre in Information Communication and Knowledge Technologies
- The University of Manchester
- Technische Universität Darmstadt
- Institut National de la Recherche Agronomique
- European Molecular Biology Laboratory
- Agro-Know IKE
- Stichting LIBER
- Universiteit van Amsterdam
- The Open University
- École Polytechnique Fédérale de Lausanne
- Fundacion Centro Nacional de Investigaciones Oncologicas Carlos III
- The University of Sheffield
- GESIS: Leibniz-Institut Für Sozialwissenschaften
- Greek Research and Technology network
- Frontiers Media
- University of Stirling
Publications
Shardlow, M., Nguyen, N. T. H., Owen, G., Turner, S., O'Donovan, C., Leach, A., McNaught, J. and Ananiadou, S. (In Press). A New Corpus to Support Text Mining for the Curation of Metabolites in the ChEBI Database. In Proceedings of LREC 2018
Przybyla, P., Shardlow, M., Aubin, S., Bossy, R., Eckart de Castilho, R., Piperidis, S., McNaught, J. and Ananiadou, S. (2016). Text Mining Resources for the Life Sciences. Database: The Journal of Biological Databases and Curation: baw145
References
Stelios Piperidis (2012). The META-SHARE Language Resources Sharing Infrastructure: Principles, Challenges, Solutions. In Proceedings of the Eighth International Conference on Language Resources and Evaluation (LREC' 12), 23-25 May, Istanbul, Turkey. European Language Resources Association (ELRA).
D. Ferrucci and A. Lally (2004) UIMA: An Architectural Approach to Unstructured Information Processing in the Corporate Research Environment, Nat. Lang. Eng., vol. 10, no. 3-4, pp. 327–348.
Kano, Y., Miwa, M., Cohen, K. B., Hunter, L., Ananiadou, S. and Tsujii, J. (2011). U-Compare: a modular NLP workflow construction and evaluation system. IBM Journal of Research and Development, 55(3), 11:1 - 11:10
Kano, Y., Baumgartner Jr., W. A, McCrochon, L., Ananiadou, S., Cohen, K. B., Hunter, L. and Tsujii, J. (2009). U-Compare: share and compare text mining tools with UIMA. Bioinfomatics, 25(15), 1997-1998
I. Gurevych, M. Mühlhäuser, C. Müller, J. Steimle, M. Weimer, and T. Zesch (2007). Darmstadt Knowledge Processing Repository Based on UIMA. In Proceedings of the First Workshop on Unstructured Information Management Architecture at Biannual Conference of the Society for Computational Linguistics and Language Technology.
U. Hahn, E. Buyko, R. Landefeld, M. Mühlhausen, M. Poprat, K. Tomanek, and J. Wermter (2008). An overview of JCoRe, the JULIE lab UIMA component repository. In LREC'08 Workshop 'Towards Enhanced Interoperability for Large HLT Systems: UIMA for NLP', pp. 1-7.
H. Cunningham, D. Maynard, K. Bontcheva, and V. Tablan (2002). GATE: A framework and graphical development environment for robust NLP tools and applications. In Proceedings of the 40th Anniversary Meeting of the Association for Computational Linguistics.
R. Rak, A. Rowley, W. Black, and S. Ananiadou (2012). Argo: an integrative, interactive, text mining-based workbench supporting curation, Database (Oxford)., p. bas010, 2012.
R. Rak, R. Batista-Navarro, A. Rowley, J. Carter, and S. Ananiadou (2013). Customisable Curation Workflows in Argo. In Proceedings of the Fourth BioCreative Challenge Evaluation Workshop vol. 1., 2013, pp. 270-278.
Schäfer, U. (2006). Middleware for creating and combining multi-dimensional NLP markup. in Proceedings of the 5th Workshop on NLP and XML. ACL. 81-84.