

Text Mining Methods for Real Time Intelligence on Graphene Enterprise
Introduction
The project aims to develop new data sources and methods for real-time intelligence to understand and map enterprise development and commercialisation in a rapidly emerging and growing new technology. More specifically, the project focusses on new venture and small and mid-size (SME) enterprise development and commercialisation of graphene. This is a nanoscale two-dimensional material with exceptional properties holding great promise for path-breaking applications across a range of domains including electronics, medicine, batteries, and sensors. The field is expanding rapidly, with thousands of new patents and hundreds of companies already entering the graphene domain.
Project goals
The project will develop novel and scalable methods to mine and combine information from three sources:- unstructured enterprise webpages;
- unstructured data from Twitter; and
- data from established structured databases, including data on patenting.
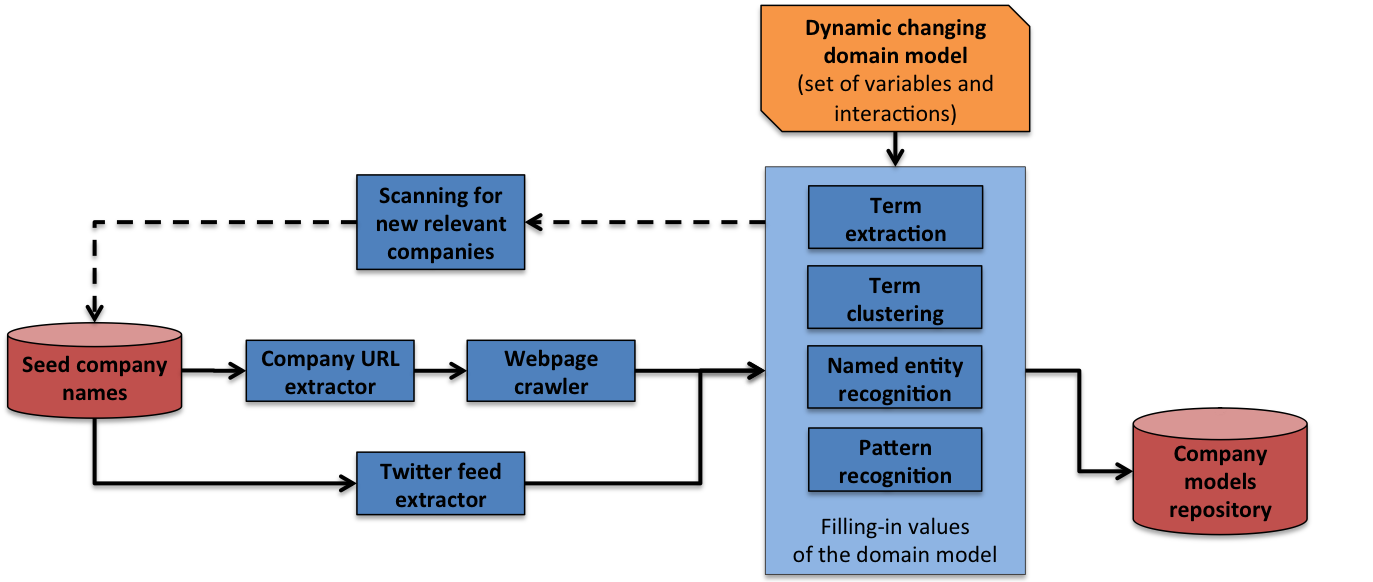 Web pages are used to extract information on enterprise business strategies, trials, tests and new products, funding, managerial and ownership developments, and relationships with other businesses and research organisation.
Twitter feeds are accessed and sourced to provide data on fast-breaking developments related to graphene, including developments associated with start-ups and SMEs.
Databases on publications and patent applications (such as the Web of Knowledge and Derwent Innovations) are accessed to validate company names and corroborate the presence (or absence) of intellectual property applications and grants by graphene-related topic areas.
Web pages are used to extract information on enterprise business strategies, trials, tests and new products, funding, managerial and ownership developments, and relationships with other businesses and research organisation.
Twitter feeds are accessed and sourced to provide data on fast-breaking developments related to graphene, including developments associated with start-ups and SMEs.
Databases on publications and patent applications (such as the Web of Knowledge and Derwent Innovations) are accessed to validate company names and corroborate the presence (or absence) of intellectual property applications and grants by graphene-related topic areas.
Outputs from the information extraction suite are stored in a repository at processing time, so that the information is available on the fly at demonstration time. For instance, users can retrieve graphene based products grown on specific substrates (e.g., epitaxial graphene grows on SiC), properties of graphene (e.g., conductivity, flexibility), which companies produce which products, information about companies, e.g., location, partnerships, funders, social media environments used.
Project information
The project is funded by NESTA.
Project team
Prof. Sophia Ananiadou, Mr. William Black, Mr. Jacob Carter, Dr. Ioannis Korkontzelos, Mr. Claudiu Mihăilă, Mr. Paul Thompson