
Integrated Social History Environment for Research (ISHER) - Digging into Social Unrest
ISHER is one of the fourteen projects that won the second Digging Into Data Challenge, a competition to promote innovative humanities and social science research using large-scale data analysis. 67 international teams competed in the challenge.Summary
Social historians and other researchers rely on text data for their research. These data are increasingly available in electronic form, but researchers are hampered in discovering information and answers to questions, as available exploratory tools are inadequate: research questions currently take much manual effort to answer or remain un(der)answered. To mitigate this, we shall develop an integrated environment using sophisticated text mining tools.
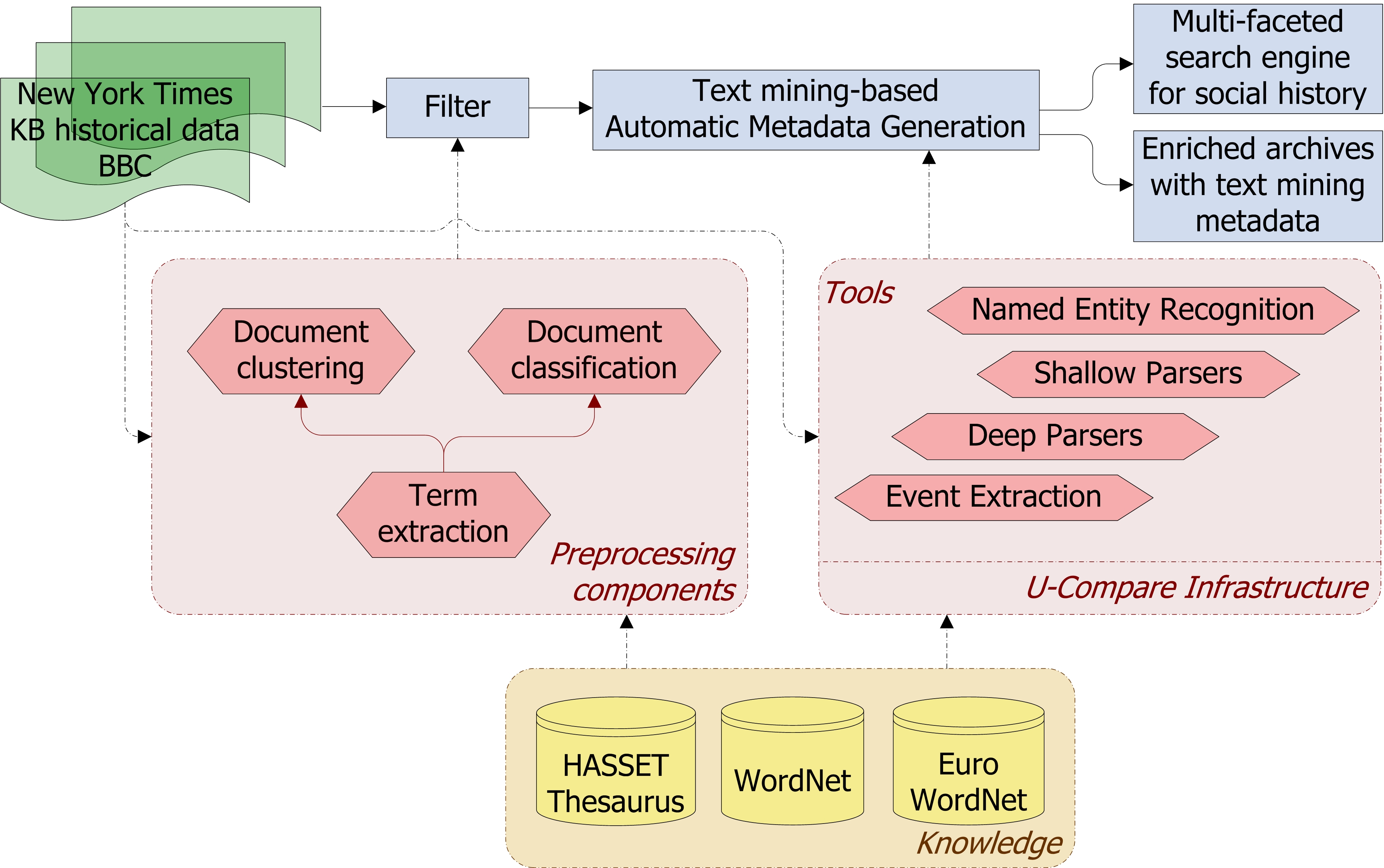
In particular, we will develop a digital humanities toolkit to facilitate basic knowledge discovery in social history research. Our text mining-based search system will supply a powerful new transformational research tool for the exploration and discovery of patterns and facts in primary historical sources originating from the digitised historical newspaper archives of the New York Times (NYT) and the National Library of the Netherlands (KB). It will provide social historians and social scientists with the means to detect and associate events, trends, people, organisations, and other entities of specific interest to social historians, related to social unrest.
Objectives
ISHER aims to enhance search over digitised resources for social history. Enhancement comes through text mining-based rich semantic metadata extraction for collection indexing, clustering and classification. This then allows semantic search while reducing the manual costs currently involved in such activities.
Interoperability of text mining tools is a key objective and an organizing principle for the software architecture of our project. IBM's Unstructured Information Management Architecture (UIMA) forms the basis of our interoperable text mining platform U-Compare, which has over 50 text mining components in its library, and is extensible so can accommodate ISHER’s requirements by including also text mining tools from third parties.
Outputs and Outcomes
The output of the project will be an integrated social history environment for research (ISHER) - which will also be re-usable for other types of humanities research. The outcome for social historians will be a transformation in their work, due to enrichment of digital archives with text mining semantic metadata, enabling users to investigate collections through advanced semantic search, in ways they could not do before.
Block diagram describing the architecture of ISHER
{kind=link}
ACE 2005 Metaknowledge annotation - As part of the project, we developed an annotation scheme to enrich events in news-related text with various information reating to their interpretation, including modality, subjectivity, source, polarity and specificity. We have annotated events within the ACE 2005 English corpus according to thes scheme. The annotations are intended to allow the training of systems that can offer more advanced semantic search and filtering capabilities.
The work is described in the following article:
Thompson, P., Nawaz, R., McNaught, J. and Ananiadou, S. (2016). Enriching News Events with Meta-knowledge Information. Language Resources and Evaluation. DOI: 10.1007/s10579-016-9344-9
The annotations, guidelines and a program that cobmines the new annotations with the existing annotations in the ACE 2005 corpus, may be downloaded from the ACE 2005 Meta-knowledge webpage, which also explains the work in greater detail.
Project information
The project started in January 2012 and is funded by JISC until July 2013.
Project Team
Principal Investigator: Prof. Sophia Ananiadou
Co-Investigator: Mr. John McNaught
Researchers: Dr. Ioannis Korkontzelos, Mr. Paul Thompson, Dr. Raheel Nawaz and Mr. William Black
Software Engineer: Jacob Carter
Demo
ISHER-NYT demo - search environment for New York Times articles from 1987 to 2007, based on entities and events.
Publications
Thompson, P., Nawaz, R., McNaught, J. and Ananiadou, S. (2016). Enriching News Events with Meta-knowledge Information. Language Resources and Evaluation. DOI: 10.1007/s10579-016-9344-9
Miwa, M., Thompson, P., Korkontzelos, I. and Ananiadou, S. (2014). Comparable Study of Event Extraction in Newswire and Biomedical Domains. In Proceedings of Coling 2014
Mihaila, C., Kontonatsios, G., Batista-Navarro, R. T. B., Thompson, P., Korkontzelos, I. and Ananiadou, S. (2013). Towards a Better Understanding of Discourse: Integrating Multiple Discourse Annotation Perspectives Using UIMA. In: Proceedings of the 7th Linguistic Annotation Workshop and Interoperability with Discourse, Association for Computational Linguistics, Sofia, Bulgaria, pp. 79-88 (LAW Challenge Award)
Thompson, P., Nawaz, R., Korkontzelos, I., Black, W.J., McNaught, J. and Ananiadou, S. (2013). News Search Using Discourse Analytics. In Proceedings of the Digital Heritage 2013 International Congress
Ananiadou, S., Thompson, P. and Nawaz, R. (2013). Enhancing Search: Events and their Discourse Context. Computational Linguistics and Intelligent Text Processing, Lecture Notes in Computer Science, Volume 7817, pages 318-334, Springer.
Batista-Navarro, R. T. B., Kontonatsios, G., Mihăilă, C., Thompson, P., Rak, R., Nawaz, R., Korkontzelos, I. and Ananiadou, S. (2013). Facilitating the Analysis of Discourse Phenomena in an Interoperable NLP Platform. Computational Linguistics and Intelligent Text Processing, Lecture Notes in Computer Science, Volume 7816, pages 559-571, Springer.
Kontonatsios, G., Korkontzelos, I., Kolluru, B., Thompson, P. and Ananiadou, S. (2013). Deploying and Sharing U-Compare Workflows as Web Services. Journal of Biomedical Semantics, 4:7
Kontonatsios, G., Korkontzelos, I. and Ananiadou, S. (2012). Developing Multilingual Text Mining Workflows in UIMA and U-Compare. In Proceedings of the 17th International conference on Applications of Natural Language Processing to Information Systems, pp. 82 - 93, Springer.
Kontonatsios, G., Korkontzelos, I., Kolluru, B. and Ananiadou, S. (2011). Adding Text Mining Workflows as Web Services to the BioCatalogue. In Proceedings of the 4th International Workshop on Semantic Web Aplications and Tools for the Life Sciences (SWAT4LS)
Zervanou, K., During, M., Hendrickx, I. and van den Bosch, A. (2014). Documenting Social Unrest: Detecting Strikes in Historical Daily Newspapers. Social Informatics. Lecture Notes In Computer Science. Volume 8359, 120-133. Springer
Zervanou, K., Korkontzelos, I., van den Bosch, A. and Ananiadou, S. (2011). Enrichment and Structuring of Archival Description Metadata. In Proceedings of the 5th ACL Workshop on Language Technology for Cultural Heritage, Social Sciences, and Humanities, pp. 44-53
Project Partners
Prof. Sophia Ananiadou, The University of Manchester
Prof. Antal van den Bosch, Radboud University Nijmegen
Prof. Dan Roth, University of Illinois at Urbana-Champaign
Futher information
- ISHER presentation.
- Contact us using the project email address.
- Follow the project on Twitter.
- ISHER page at the University of Illinois at Urbana-Champaign.
Featured News
- AI for Research: How Can AI Disrupt the Research Process?
- ELLIS Workshop on Misinformation Detection - Presentation slides now available
- 1st Workshop on Misinformation Detection in the Era of LLMs (MisD)- 23rd June 2025
- Prof. Sophia Ananiadou accepted as an ELLIS fellow
- Invited talk at the 15th Marbach Castle Drug-Drug Interaction Workshop
- BioNLP 2025 and Shared Tasks accepted for co-location at ACL 2025
- Prof. Junichi Tsujii honoured as Person of Cultural Merit in Japan
- Participation in panel at Cyber Greece 2024 Conference, Athens
- New Named Entity Corpus for Occupational Substance Exposure Assessment
![]() Featured News Feed
Featured News Feed
Other News & Events
- CL4Health @ NAACL 2025 - Extended submission deadline - 04/02/2025
- Shared Task on Financial Misinformation Detection at FinNLP-FNP-LLMFinLegal
- FinNLP-FNP-LLMFinLegal @ COLING-2025 - Call for papers
- Keynote talk at Manchester Law and Technology Conference
- Keynote talk at ACM Summer School on Data Science, Athens
![]() Other News Feed
Other News Feed


![]()




