
ACELA
The ACELA (ACcElerated Annotation) tool aims to reduce the human effort required to produce a gold standard corpus of named entity (NE) annotations. The process of annotation is similar to active learning, in that it is performed as an iterative and interactive process between the human annotator and a machine-learned NE tagger. This is illustrated in Figure 1.
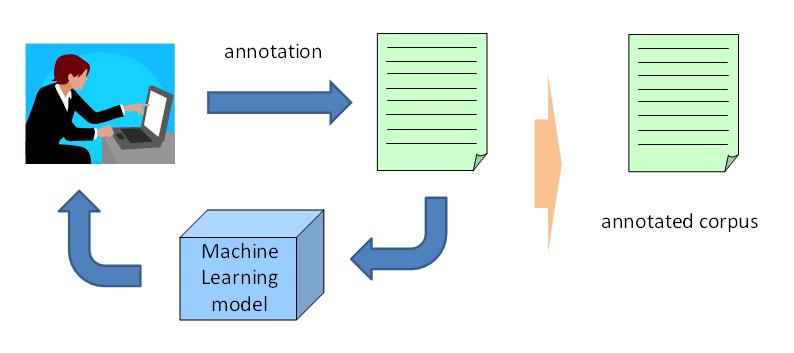 Figure 1: The ACELA annotation process
Figure 1: The ACELA annotation process
The aim of the tool is to ensure that all NEs of a given type are annotated in a given corpus with minimum effort from the human annotator. Only those sentences that are most likely to contain NEs of the target type (according to the predictions of the tagger) are displayed for the human to annotate, which means that it is not necessary to read through all sentences in the corpus that do contain relevant entities.
At each iteration of the process, the NE tagger is re-trained on all available sentences that have been human annotated, meaning that it makes increasingly accurate predictions about which sentences contain named entities. The tool also makes estimates about the number of entities in the corpus that have been annotated by the human (coverage), and the annotation process stops when the figure is close to 100%.
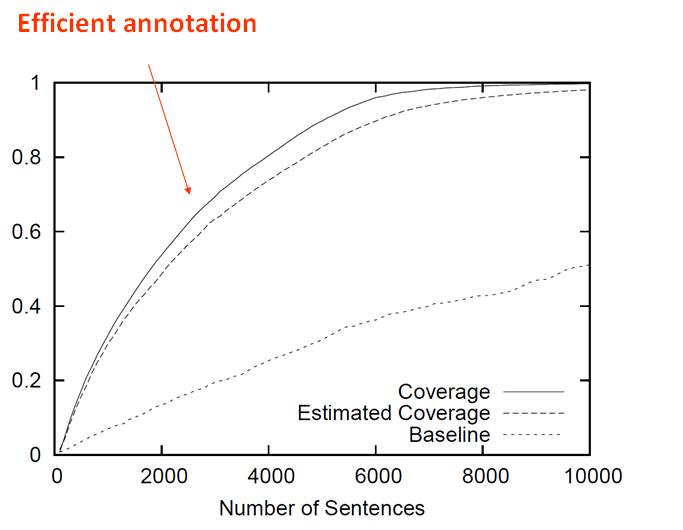 Figure 2: Efficiency of ACELA annotation
Figure 2: Efficiency of ACELA annotation
Figure 2 illustrates the efficiency of the tool for annotating NEs of type DNA in the GENIA corpus. Using manual annotation alone, it can be expected that after manually annotating 10,000 sentences in a sequential fashion, only about half the entities in the corpus will have been annotated. However, using the ACELA tool to predict the sentences most likely to contain the relevant NEs, annotating the same number of sentences achieves almost 100% coverage of all DNA entities in the corpus.
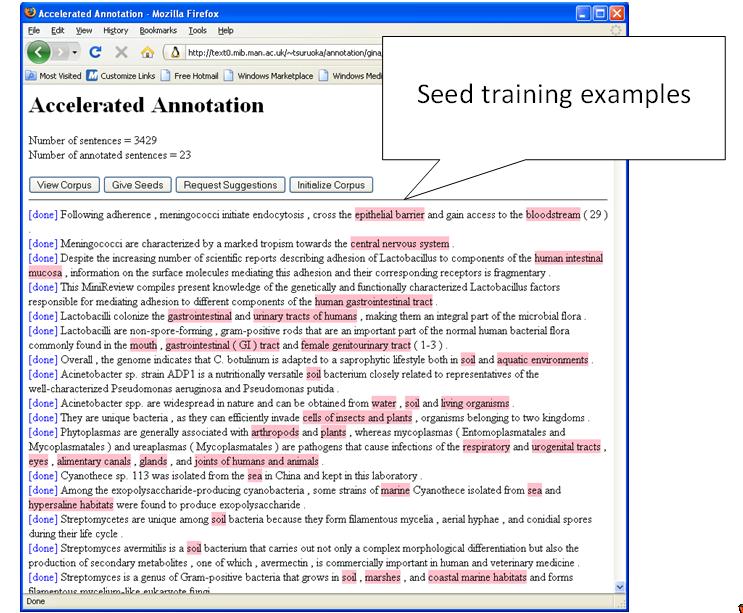 Figure 3: ACELA web interface
Figure 3: ACELA web interface
ACELA provides a web-based user interface, part of which is illustrated in Figure 3. The process begins with the user providing a number of example entities of the target category ("seeds"), which the algorithm uses to start making predictions.
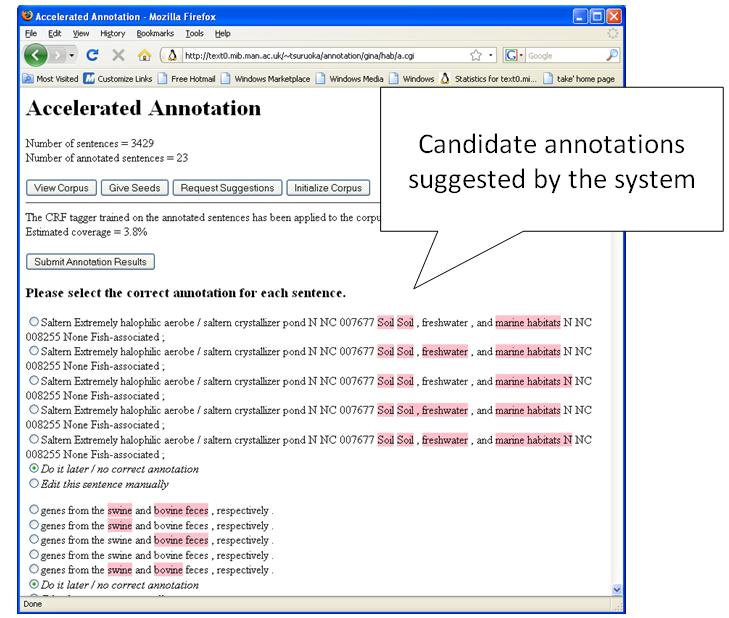 Figure 4: Annotation in ACELA
Figure 4: Annotation in ACELA
The main annotation screen of the ACELA interface is shown in Figure 4. For each sentence predicted to contain NEs, the tool makes a number of alternative suggestions about the correct NEs in the sentence. The task of the annotator is to select the correct prediction for each sentence.
References
Further details about the annotation framework used by ACELA are available in the following paper:
Yoshimasa Tsuruoka, Jun'ichi Tsujii and Sophia Ananiadou. 2008. Accelerating the annotation of sparse named entities by dynamic sentence selection, BMC Bioinformatics, 9(Suppl 11):S8.
Contact
If you are interested in using ACELA, please contact us.