
ACE 2005 Meta-knowledge Annotation
Description
The ACE 2005 corpus is a collection of news-related documents from various spoken and written sources, which have been annotated with various levels of semantic information, including entities (e.g., names of people, places, weapons, etc.) and events, which link entities with situations described in the text. For example, an event may correspond to a description of who killed who, with which weapon, and where, etc. The corpus provides the means to train machine learning information extraction systems to extract semantic information automatically. This can lead, e.g. ,to the development of sophisticated semantic search systems, in which queries can be based on entities and/or events.
An important point about events is that their correct and complete interpretation is often not possible without considering additional contextual information that is present within the surrounding text. For example, events may correspond to definite facts or speculated information; the information expressed by events may come from different types of source, e.g., the author of the text, or alternatively somebody else, who may be closely linked to the event, or more distanced from it. Thus, knowing the type of source can often be important in determining the reliability of the information. Additionally, the source may express a positive or negative opinion about the event.
We refer to these and other types of contextual, interpretative information about events as meta-knowledge. By annotating various different aspects of meta-knowledge at the level of events, we can train more sophisticated information extraction systems, which are able to automatically assign interpretative information about each event. This can allow, for example, the development of more advanced semantic search systems, in which definite events can be isolated from speculated events, differing opinions towards a particular type of event can be compared, etc.
Building upon previous work, in which we developed a meta-knowledge scheme for events in biomedical text, we have developed an adapted scheme that is more suited for application to events in news-related text. We have manually applied the scheme to the 5,349 event instances in the 599 documents of the original ACE 2005 corpus. Whilst the original ACE 2005 corpus includes some basic annotation that can be classed as meta-knowledge, the new meta-knowledge annotation effort provides new types of interpretative information, as well as enriching existing meta-knowledge information, and providing a finer-grained level of detail.
Availability
The new meta-knowledge annotations may be downloaded for research purposes (please observe the terms of the licence below).
NOTE: The annotations provided in the download rely on the availability of the ACE 2005 corpus and its original annotations, although ACE 2005 is NOT included with the meta-knowledge annotation download. The ACE 2005 corpus is separately licensed by the Linguistic Data Consortium (LDC), and it must be obtained from them.
We provide the following for download:
- Meta-knowledge annotations, in a custom XML format. Within each XML file, annotation offsets refer to positions in the corresponding text file of the original ACE 2005 corpus, and there are also links to annotations in the original corpus. A DTD for the custom meta-knowledge XML annotation format is included
- The annotation guidelines used by annotators to perform the annotation task.
- A proposed, integrated DTD that combines information in the original ACE annotation files with information in the new meta-knowledge annotation files.
- A Java program that combines the information in the two types of annotation files according to the proposed augmented DTD (assuming that the original ACE 2005 corpus has been obtained).
Please see the separate ACE Meta-knowledge annotation format page for further details of the custom XML format, the integrated DTD and the Java program to combine them
Motivation
The digital information era has made vast and continually growing amounts of data available in digital form. This potentially provides a very rich source of historical data for researchers. However, as the amount of data available grows, researchers face increasing difficulties in finding information that is of interest to their research questions. Simple keyword-based search systems are usually not adequate for this purpose, as researchers typically have to spend a lot of time trawling through volumes of mostly irrelevant data returned by their searches.
Text mining offers a solution to such problems, by automatically deriving rich semantic metadata about documents in a collection. This may include named entities (e.g., people, locations, organisations) and possibly more sophisticated information about how these entities are linked together in documents to describe events (e.g., attacks, arrests, deaths, births). For example, consider the following sentence:
(S1) Oscar Pistorious killed his girlfriend in Pretoria last night.
The sentence describes a death event (indicated by the word killed), in which Oscar Pistorious is the agent/perpetrator and his girlfriend is the victim/subject of the event. The sentence also provides information about the timing (i.e., last night) and the location (i.e., Pretoria) of the event. This information can be systematically organised using an event representation scheme. For example, Figure 1 shows the ACE 2005 representation of the event.
 Figure 1. ACE 2005 representation of the event mentioned in sentence S1
Figure 1. ACE 2005 representation of the event mentioned in sentence S1
Although the main focus of such annotation is on the identification of event participants, this alone is not sufficient for the correct and complete interpretation of these events. For example, the event might be described as something that has already occurred, or as something that is anticipated to occur in the future. It may be described as a definite occurrence, or there may be some degree of speculation about whether it actually happened or will happen. Furthermore, the event may correspond to the point of view of the author or that of a third party, and either party may express subjectivity or opinions towards the event. As an illustration of these subtle (but important) aspects of event interpretation, consider three more sentences (S2-S4), all of which are similar to S1 (and to each other), in that they all refer to the same event (i.e., the death of Reeva Steenkamp caused by Oscar Pistorious). However, the interpretation of the event is different in each sentence. In each case, the word or phrase denoting the death event is underlined, while words and phrases important for the correct interpretation of the event are emboldened.
(S2) Mr Pistorious told the court that he deeply regrets shooting his girlfriend.
(S3) According to unconfirmed reports, Oscar Pistorious may have fatally shot his girlfriend, Reeva Steenkamp, at his residence in Pretoria.
(S4) Mrs Steenkamp said that she holds Oscar responsible for the tragic events that led to her daughter's death.
S1 and S3 present the event as new or emerging information, while S2 and S4 mention it as already known or presupposed information. In S1, the information source of the event is the author herself; in S2 and S4, the source is someone closely in the event (i.e. Mr. Pistourious and Mrs. Steenkamp, respectively); and in S3, the information has been attributed to unknown third-party sources (i.e., unconfirmed reports). The occurrence of the event is mentioned speculatively in S3, as denoted by the word may, while S1, S2 and S4 report it with apparent certainty. Finally, S2 and S4 contain indications of negative sentiments towards the event. In S2, this is indicated by the phrase deeply regrets, while in S4, the fact that Mrs. Steenkamp holds Oscar responsible for the death of her daughter denotes her negative sentiment towards the event. In contrast, S1 and S3 do not contain any sentiment or opinion about the event.
Annotation Scheme
Meta-knowledge annotation in the original ACE 2005 corpus
The ACE 2005 corpus already includes some meta-knowledge attributes annotated at the level of events. However, as described below, we considered these inadequate to account for all types of meta-knowledge information that can frequently be derived from the textual context of events. We have thus updated this schema to take into account further and more fine-grained aspects of event interpretation. Firstly, we introduce the original event meta-knowledge attributes in ACE 2005:
- POLARITY - This value is set to Negative if it is explicitly stated that the event did not take place. Otherwise the value is set to Positive.
- TENSE - The possible values are: Past, Present, Future or Unspecified. These values are assigned according to the time that the event took place with respect to the textual anchor time (i.e., the time of broadcast or publication). Unspecified is assigned if it is not clear when the event took place or if it has taken place.
- MODALITY - The value is set to Asserted when the author or speaker makes reference to the event as though it were a real occurrence. In all other cases the value is set to Other.
- GENERICITY - This has two possible values, i.e. Specific if the event is understood as a singular occurrence at a particular place and time, or a finite set of such occurrences; otherwise, the value is set to Generic.
Limitations of meta-knowledge annotation in the original ACE 2005 corpus
Referring back to the example sentences above, it can be appreciated that the existing meta-knowledge attributes have the following limitations:
- They do not capture subjective attitudes expressed towards the event.
- The type of information source of an event is not identified
- Events that have speculation expressed towards them are not explicitly distinguished.
- No distinction is made between events being reported as "new" information and those describing "old/known" information.
- Some inconsistencies with the values of the existing attributes were discovered
Augmented meta-knowledge annotation scheme
In order to account for the limitations of the meta-knowledge annotation in the original ACE 2005 corpus, we have developed an augmented meta-knowledge scheme, as shown in Figure 2.
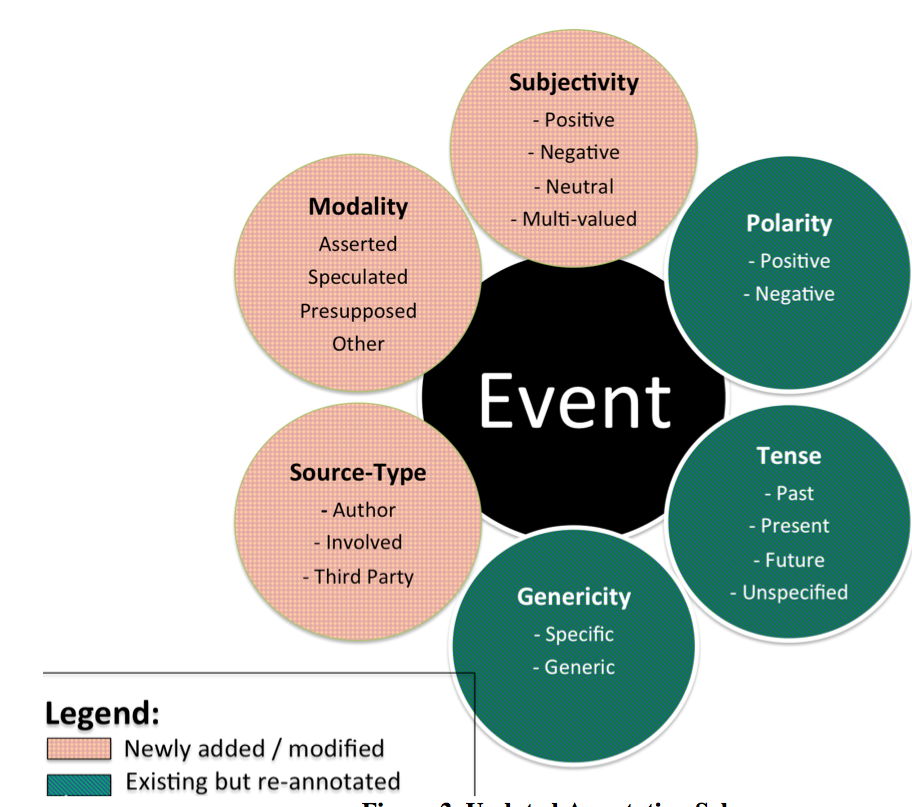 Figure 2. Augmented ACE 2005 meta-knowledge annotation scheme
Figure 2. Augmented ACE 2005 meta-knowledge annotation scheme
Specifically, we have made the following changes to the original ACE meta-knowledge annotation scheme:
-
We added two new attributes:
- SOURCE-TYPE - Captures the type of source or origin of the information being expressed by the event. Possible values are: Author, when events are presented as information provided by the author, or as representing their own point of view; Involved, when information expressed by the event is attributed to a specified source who is somehow involved or has close links to the actions described by the event; and Third-Party, denoting that the information expressed by the event can be attributed to a third party source that is not involved in the event. For the latter two values, the phrase in the text denoting the information source is identified and linked to the event, if such a phrase is present. We distinguish between named and unnamed third-party sources, since unnamed sources are often considered less reliable than named sources.
- SUBJECTIVITY - Captures explicit expressions of subjectivity towards the event as a whole by the identified information source. Possible values are: Positive, when the information source evaluates the event as good for themselves; Negative, when an event is evaluated as bad or harmful from the perspective of the source; Multi-valued, when two or more sources express opposite (i.e., positive and negative) sentiments about the same event; and Neutral, when no explicit subjectivity information is specified towards an event.
- We refined the MODALITY attribute, by adding two new values (i.e., Speculated and Presupposed). We also refined the definitions of the two existing values (i.e., Asserted and Other). According to the new definitions, Asserted is only to be assigned to definite events that introduce new information into the discourse, while Presupposed events are definite events that describe situations that are assumed to be already known by the listener/reader, or have been previously mentioned within the discourse. The Speculated value is assigned to events for which there is some explicitly expressed uncertainty regarding their occurrence, while Other is assigned to events that do not fit into any of the above categories.
- We have refined the annotation guidelines for the remaining three attributes (i.e., POLARITY, GENERICITY, and TENSE) to further clarify the distinction between the values of these attributes. We have re-annotated these three attributes, although we have not changed the original values.
- We have annotated the cue words/phrases that provide evidence for the assignment of particular attribute values (such as the emboldened phrases in the examples above), and linked them to the appropriate events. Previous meta-knowledge work has shown that identifying such cues can improve the accuracy of meta-knowledge attribute prediction.
Evaluation
Approximately one fifth of the corpus was double annotated to allow inter-annotator agreement (IAA) rates to be calculated, and to ensure the consistency of the annotations. Our results serve to demonstrate that in general, the annotations can be considered to be of a high quality.
We calculated IAA in terms of Kappa for each of the meta-knowledge attribute values, with values ranging from 0.530 to 0.871. According to a scale of interpretations for these scores, the agreement achieved for the GENERICITY and POLARITY attributes is "almost perfect", for TENSE, MODALITY and SUBJECTIVITY, agreement is "substantial" and for SOURCE-TYPE, the agreement level is considered "moderate".
We have also calculated agreement for cue phrase identification, in term of positive specific agreement. Considering cases where both annotators agree on the values of meta-knowledge attributes, this was 0.895 for exact matches (i.e., where the cues phrases annotated by both annotators must match exactly) and 0.948 for relaxed matches (i.e., where it is sufficient for the cue phrases chosen by the different annotators to include some common parts, even if they do not match exactly).
ACE 2005 Meta-knowledge annotation licence

The meta-knowledge annotations for the events in the ACE 2005 corpus were created at the National Centre for Text Mining (NaCTeM), School of Computer Science, University of Manchester, UK. They are licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License. Please attribute NaCTeM when using the meta-knowledge annotations and cite the following paper:
Thompson, P., Nawaz, R., McNaught, J. and Ananiadou, S. (2016). Enriching News Events with Meta-knowledge Information. Language Resources and Evaluation. DOI: 10.1007/s10579-016-9344-9