Efficient HPSG Parsing
1. Introduction
Deep syntactic analysis by lexicalized grammar parsing offers a solid basis for intelligent text processing, such as question-answering, text mining, and machine translation. In those tasks, however, a large amount of text has to be processed to build a useful system. One of the main difficulties of using lexicalized grammars for such large-scale applications is the inefficiency of parsing caused by complicated data structures used in such grammars.
We achieved a 10-fold speed-up in HPSG parsing by combining three techiniques: Supertagging, CFG-filtering, and deterministic disambiguation. The process of HPSG parsing comprises of two stages:
- Lexical assignment: lexical entries are assigned to words in the input sentence.
- Schema application: syntactic and semantic structures of the input sentence are computed by combining the lexical entries by applying the rule schemata.
Two different types of ambiguities exist respectively in the above two steps. We need to disambiguate them to get a proper analysis of the input sentence:
- Lexical disambiguation: a word has several possible lexical entries that correspond to the different usages of the word. We need to select an appropriate one which matches the usage of the word in the input sentence.
- Combinatorial disambiguation: there are several different ways to combine the lexical entries even after the lexical assignments are fixed. We need to select the most plausible one.
Supertagging is an existing pre-processing technique for lexicalzed grammar parsing that makes the parsing faster by selecting only a small number of lexical entries for each word and hence reducing the cost of the combinatorial dsiabmbiguation. We combined Supertagging with another technique called CFG-filtering to do more powerful lexical disambiguation as the pre-processing. By doing this, we can use a very simple algorithm, deterministic disambiguation, for the combinatorial disambiguation. Experimental results showed that our system achieves a 10-fold speed-up compared with previous HPSG parsers. The remainder of this section describes the details of the parsing system and shows the experimental results.
2. A fast HPSG parsing system
A schematic overview of our parsing system is shown in Figure 1. We firstly apply to the input sentence the pre-processing technique where Supertagging and CFG-filtering are combined. The result of the pre-processing stage is a list of globally consistent lexical entry assignments (supertag sequences), which is sorted in the descending order of the sum of the scores of the lexical entries given by the Supertagger. We input the supertag sequences to the deterministic disambiguation module one by one until a well-formed parse tree is obtained. We describe the sub-modules in the system below.
3. Supertagging
In the lexicalized grammars, characteristics of a word are represented in a data structure called a lexical entry. A word generally has several different usages (e.g., transitive and intransitive usages of “run”). Several lexical entries are hence associated to a single word in the lexicon. Supertagging (Bangalore and Joshi, 1999) is a pre-processing technique where only a few lexical entries for a word are selected based on the context of the word (e.g., surrounding words and their part-of-speeches). By selecting a small number of lexical entries for each word in the pre-processing stage, the parsing thereafter becomes faster. Supertagging is a simple and fast process but often gives globally inconsistent combination of lexical entry assignments since its predictions are based only on information of limited types. The parser fails on such inconsistent lexical entry assignments since it cannot find a well-formed parse tree on them. In several previous systems based on Supertagging, this problem was solved by gradually increasing the number of lexical entries and repeating the parsing until the parser finds a well-formed parse tree.
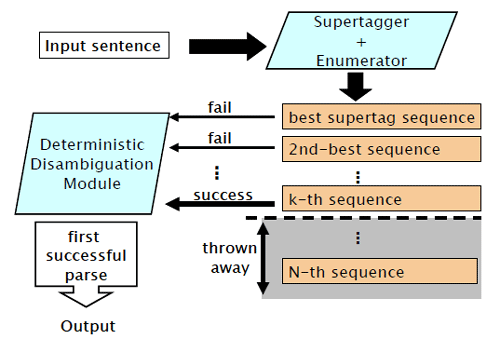 Figure 1: Overview of the parsing system
Figure 1: Overview of the parsing system4. CFG-filtering
CFG-filtering (Torisawa et al, 2000) is a technique to speed-up HPSG parsing by using a CFG that approximates the original HPSG grammar. The approximating CFG is used to efficiently eliminate the analyses of a sentence that are not allowed in the original HPSG. We developed an algorithm that enumerates globally consistent combinations of lexical entries by combining the CFG-filtering technique with Supertagging. The approximating CFG is not equivalent to the original HPSG in general. A combination of lexical assignments thus may not have a well-formed parse tree, even when the lexical assignments are judged as globally consistent by using the approximating CFG. However we found in the experiment that such cases are very rare.
5. Deterministic disambiguation
The lexical ambiguity in the input sentence is totally resolved after the pre-processing algorithm described above. That is, each word in the input sentence is assigned only one lexical entry. It is possible to use a very simple and efficient algorithm to resolve the combinatorial ambiguity and find a parse tree on such input. Specifically, we used an algorithm based on the shift-reduce parsing algorithm. In this algorithm, the combinatorial ambiguity is resolved by using a classifier in a greedy manner. It thus does not create and store multiple partial analyses as in the dynamic-programming-based parsers used in the previous approaches. We could greatly reduce the number of operations to create and copy the complex data structures representing the partial analyses, and as a result the parsing time shortened.
Parsers |
Sentences <= 40 words |
|||
|---|---|---|---|---|
LP (%) |
LR (%) |
F1 (%) |
Avg. time (ms) |
|
Proposed method |
87.10 |
86.91 |
87.01 |
15 |
(Ninomiya et al., 2006) |
87.66 |
86.53 |
87.09 |
155 |
(Miyao and Tsujii, 2005) |
85.33 |
84.83 |
85.08 |
509 |
Parsers |
Sentences <= 100 words |
|||
|---|---|---|---|---|
LP (%) |
LR (%) |
F1 (%) |
Avg. time (ms) |
|
Proposed method |
86.90 |
86.71 |
86.80 |
19 |
(Ninomiya et al., 2006) |
87.35 |
86.29 |
86.81 |
183 |
(Miyao and Tsujii, 2005) |
84.96 |
84.25 |
84.60 |
674 |
|
LP (%) |
LR (%) |
F1 (%) |
Success (%) |
Avg. time (ms) |
|---|---|---|---|---|---|
W/o CFG-filter |
88.33 |
84.09 |
86.15 |
79.56 |
556 |
W/ CFG-filter |
86.72 |
86.21 |
86.46 |
97.69 |
18 |
Submodule |
Avg. time (%) |
|---|---|
POS tagging |
2.7 ms (17%) |
Supertagging |
1.4 ms (9%) |
Enumeration of supertag sequences |
3.8 ms (23%) |
Deterministic disambiguation |
5.2 ms (32%) |
Other |
3.1 ms (19%) |
|
|
Total |
16.3 ms |
6. Evaluation
We evaluated this system through experiments using the Penn Treebank. We used the Enju HPSG English grammar (Miyao et al., 2005) in all the experiments. Table 1 shows the results of the comparative experiments with the previous HPSG parsers. All the figures in the table are ones for the same HPSG grammar and the test set. LP, LR, and F1 in the table are metrics of the accuracy of the parsing results. Avg. time is the average of the parsing time for a senentece. Ninomiya et al.’s parser (2006) is based on Supertagging and the dynamic-programming-based parser. Miyao and Tsujii’s parser does not use Supertagging and only uses dynamic-programming-based parser. The results show the proposed method achieves 10-fold speed-up while giving comparatively accurate parse results.
Table 2 shows the parsing results with and without the CFG-filter. The column headed “Success” shows the fraction of the sentences on which the parser gives a well-formed parse tree. The results show that the use of CFG-filter improves the rate of successful parse and also greatly decreases the processing time.
Table 3 presents a breakdown of the average processing time per a sentence. It shows the most time-consuming part in the system is the deterministic disambiguation, which consumes 32% of the total processing time. Most of the processing time in the deterministic disambiguation module is used for the operations on the typed feature structures, which are used to represent lexical entries and phrasal constituents. By the nature of the disambiguation algorithm, the number of the operations on the typed feature structures is almost the minimum to create a parse tree for a sentence. Further speed-up, say, 3-fold speed-up, is therefore very difficult. To put it the other way around, the efficiency of HPSG parsing was improved to nearly its limit by the proposed method.
7. Conclusion and future work
We developed an efficient parsing system for HSPG, where Supertagging, CFG-filtering, and deterministic disambiguation are combined. Experimental results showed our system gives comparatively accurate parsing results with 10-fold speed-up compared with previous HPSG parsers. Our future work is to improve the accuracy of the parser while keeping the parsing speed.
Related papers
- Miyao Yusuke and Tsujii Jun’ichi, Probabilistic disambiguation models for wide-coverage HPSG parsing, In the Proceedings of ACL 2005, Ann Arbor, Michigan, pp. 83-90, June 2005.
- Ninomiya Takashi, Matsuzaki Takuya, Tsuruoka Yoshimasa, Miyao Yusuke, and Tsujii Jun’ichi, Extremely lexicalized models for accurate and fast HPSG parsing, In the Proceedings of EMNLP 2006, Sydney, Australia, pp. 155-163, July 2006.
- Matsuzaki, Takuya, Yusuke Miyao and Jun'ichi Tsujii. Efficient HPSG Parsing with Supertagging and CFG-filtering, In the Proceedings of the Twentieth International Joint Conference on Artificial Intelligence, Hyderabad, India, pp. 1671-1676, January 2007.
References
- Miyao Yusuke, Ninomiya Takashi, and Tsujii Jun’ichi, Corpus-oriented grammar development for acquiring a Head-driven Phrase Structure Grammar from the Penn Treebank, In the Proceedings of IJCNLP 2004, Hainan Island, China, pp.684-693, 2004.
- Kentaro Torisawa, Kenji Nishida, Miyao Yusuke and Tsujii Jun’ichi, An HPSG parser with CFG filtering , Natural Language Engineering, 6(1), pp. 63-80, 2000.
- Srinivas Bangalore and Aravind K. Joshi, Supertagging: An Approach to Alomost Parsing, Computational Linguistics, 25(2), pp. 237-265, 1999.